背景
最近的插件TabManager中遇到了很多图片相关的问题,我觉得是多模态下,一个agent想要处理图片,避不开的,这里面有一些是多模态agent的设计相关,也有很多是页面相关的。首先我们先把多模态收敛为图片识别和图片生成的场景。
识图
对于图片识别,本质就是用户可以传图片内容给大模型,以chat接口为例,入参大概是这样:
{
"role": "user",
"content": [
{
"type": "text",
"text": "请描述图片内容"
},
{
"type": "image_url",
"image_url": "https://www.example.com/image.png"
}
]
}
其中image_url字段可以是这种网络上的图片,也可以是本地的图片,本地图片会用base64编码后传输,而base64url的字符串长度非常长,例如1M的图片,大概就有100w+个字符,这也是后面要重点讨论的问题。
除了用户输入的内容中可能有图片,工具返回的结果中也有可能有图片,例如:
[
{
"role": "user",
"content": "截图看下当前页面的内容"
},
{
"role": "assistant",
"content": null,
"tool_calls": [
{
"id": "call_HUkGShjyxDmDxKGWfA8P708X",
"type": "function",
"function": {
"name": "tab_screenshot",
"arguments": "{\"fullPage\":false,\"maxScreens\":1,\"settleMs\":250,\"tabId\":373538955,\"windowId\":373538943}"
}
}
]
},
{
"role": "tool",
"tool_call_id": "call_HUkGShjyxDmDxKGWfA8P708X",
"content": "{\"success\":true,\"imageUrl\": \"超长的b64url\"}"
}
]
但是工具调用结果中的url字段是纯字符串,如果直接把这个结果塞回llm,不光llm无法识图,而且会把上下文塞爆炸。
工具的图片结果,如何正确的让llm“看到”呢?
对于chat类型的接口,你需要识别工具返回结果,把imageUrl这个字段识别出来之后,把这个字段从文本content中剔除,然后再追加发一条user role的内容,如下:
[
{
"role": "user",
"content": "截图看下当前页面的内容"
},
{
"role": "assistant",
"content": null,
"tool_calls": [
{
"id": "call_HUkGShjyxDmDxKGWfA8P708X",
"type": "function",
"function": {
"name": "tab_screenshot",
"arguments": "{\"fullPage\":false,\"maxScreens\":1,\"settleMs\":250,\"tabId\":373538955,\"windowId\":373538943}"
}
}
]
},
{
"role": "tool",
"tool_call_id": "call_HUkGShjyxDmDxKGWfA8P708X",
"content": "{\"success\":true}"
},
{
"role": "user",
"content": [
{
"type": "text",
"text": "这是工具的图片结果"
},
{
"type": "image_url",
"image_url": "超长的b64url"
}
]
}
]
对于responses和messages类型,也就是openai和anthropic官方的接口,原生是支持工具返回图片内容的,如果是国产模型的协议适配的话,大概率是不支持的。如果是两家官方模型则没问题,形式如下:
openai请求中,output是个数组,可以放入input_image这个类型,并指定image_url放入base64编码,这种形式是可以被原生模型就能识别的。
[
{
"type": "function_call_output",
"call_id": "your_call_id_here",
"output": [
{
"type": "input_image",
"detail": "low",
"image_url": "data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAA..."
}
]
}
]
anthropic请求中,messages是个数组,可以放入image这个类型,如下,同样也能被模型识别。
{
"type": "tool_result",
"tool_use_id": "toolu_01XtLYBDStQzpAAwUgSSz2fS",
"content": [
{
"type": "text",
"text": "这是工具执行结果的描述"
},
{
"type": "image",
"source": {
"type": "base64",
"media_type": "image/jpeg",
"data": "data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAA..."
}
}
]
}
结论:唯一受伤的就是chat接口,国模很多虽然支持anthropic协议,但是不一定支持image类型的tool_result。
生图
生图是模型的能力,现在有2个主流的演进方向
一种是openai一直坚持的生成图片有专门的/image/generation和/image/edit接口,可以生成图片和编辑图片。
{
"model": "gpt-image-2",
"prompt": "生成一张夜上海图片",
"n": 1,
"quality": "high",
"size": "1024x1024",
"response_format": "b64_json",
"style": "vivid"
}
而edit则需要上传原图片、参考图、蒙版图,请求是这样的:
# cURL示例
curl -X POST "https://api.openai.com/v1/images/edits" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-F "model=gpt-image-2" \
-F "image=@original_image.png" \
-F "[email protected]" \
-F "prompt=Replace the cat with a dog" \
-F "n=1" \
-F "size=1024x1024" \
-F "response_format=b64_json"
另一种是gemini这种多模态模型本身不仅能识图,也能生图,直接用chat接口,并指定输出允许图片的内容,就会自己判断并返回图片,后续还可以继续会话,也就是把图片当成对话的一部分,完美融入了。
{
"model": "google/gemini-2.5-flash-image",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "Edit the image: add aurora borealis to the night sky in the masked area"
},
{
"type": "image_url",
"image_url": {
"url": "data:image/png;base64,[BASE64_ENCODED_IMAGE]"
}
},
{
"type": "image_url",
"image_url": {
"url": "data:image/png;base64,[BASE64_ENCODED_MASK]"
}
}
]
}
],
"modalities": ["image", "text"]
}
目前agent的主模型大概率不是支持原生出图的,并且现在gpt-image-2太强了,其他原生出图,基本也不会用,而是想要用gpt-image-2。所以目前openrouter都把gpt5.4和image-2两个混合成一个模型,用chat接口调用了。也就是强行把gpt也弄成google gemini的图片形式了。
{
"model": "openai/gpt-5.4-image-2",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "Replace the cat with a dog, keeping the same pose and background, cartoon style"
},
{
"type": "image_url",
"image_url": {
"url": "data:image/png;base64,xxx"
}
}
]
}
],
"modalities": ["image", "text"]
}
挑战
想要把生图功能引入到agent中,目前最可拔插的方案就是引入一个内置工具,这个工具调用可配置的generate/edit或chat接口,来生图或者改图。
挑战1: 生图工具的结果怎么正确的让llm“看到”呢?
这个挑战上面已经给出了答案:
- 1 对于chat类型的,上面提到了补一轮user消息带上这个image b64url。
- 2 对于responses和messages类型,把工具生成的结果放到特定的字段中。
这些都需要agent代码上有相应的改动。
挑战2: 改图的时候,如何在入参中传入b64?
这其实是最大的挑战,因为如果封装为一个改图的tool,他的入参就是原图url 参考图url 蒙版图url,这个url对于本地文件是b64的超长文本。模型在复述b64这种长文本的时候,因为没有逻辑很容易出现丢字符的情况,而且长文本还是会导致ctx爆炸。
挑战3: 前端session加载卡顿
我在chrome插件的storage.local中存储了会话的历史记录,也包括b64的图片,这导致在session加载的时候非常慢,主要是JSON.parse(storage.local.get("sessid")),序列化json的时候,因为超级长的b64url序列化非常慢,导致了前端的session加载卡顿,会有1-2s的不跟手的情况。
我的解决方案
引用与解引用
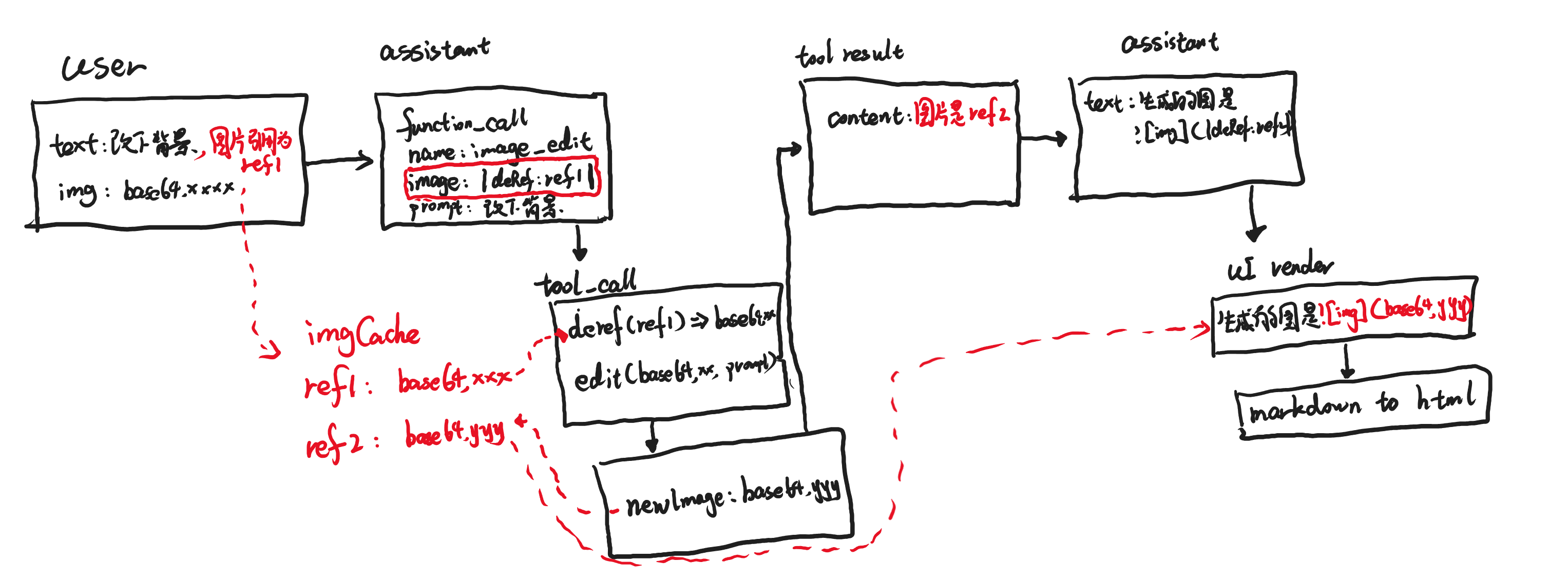
我的解决方案是构建一套图片b64的引用机制,简单说就是对b63图片进行引用,单独存储到一个session级别的缓存中Map<RefId, b64url>,然后提示词中添加说明:
如果工具调用的参数需要b64url的图片的话,请直接用`|deRef:RefId|`这个形式,不需要用b64字符串,工具会识别这个形式,自动解引用。
配套的在工具输入中含有图片的时候,自动在这个user的msg中加一段描述,并且把图片的b64url存储到缓存中,以便后续可以解引用。
用户上传的这个图片的引用id是`img_ref1`,后续如果有工具调用需要这个图片,请直接用`|deRef:img_ref1|`这个形式,不需要用b64字符串,工具会识别这个形式,自动解引用。
如果是要像用户再次展示这个图片,请用markdown语法: ``
然后在工具返回的结果中,如果是b64图片的话,要进行替换,把b64添加到缓存中,并把工具返回结果中的b64url直接删掉,换成另外一个引用描述的文本。
本次工具返回的结果是一张图片,他的引用为`img_ref2`, 后续如果有工具调用需要这个图片,请直接用`|deRef:img_ref2|`这个形式,不需要用b64字符串,工具会识别这个形式,自动解引用。
如果是要像用户再次展示这个图片,请用markdown语法: ``
然后就是解引用的部分了,在工具调用的时候,加一个统一的前置处理,查看入参中是否有|deRef:RefId|这个形式,如果有,则把这个参数替换成imgCache.get(RefId),这样真正调用到函数的入参就是b64的图片了。
大模型返回的,也是同理,在markdown渲染器中植入对这个图片形式的解析,遇到url是这个格式的,也去执行解引用。
这一套流程下来,我们发现,主模型的输出内容,不再会有原始b64url了。主模型的输出内容包括:
- 展示一下之前的图片,通过markdown语法:
给替代了。 - 调用某个工具提供的入参,也通过
|deRef:img_ref2|这个形式给替代了。
以一个场景为例:
- 1 用户输入:帮我把这张图背景改黑色. 并带有一张图片在这个输入中。
- 2 主模型输出:让我调用image_edit工具,并带有一个工具调用的item。
- 3 调用完成:返回新的图片,传给大模型结果。
- 4 主模型输出:生成的图片在这里:xx。
这是一个流程简图:
脱水与水合
前端聊天记录load加载慢的问题,本质是上图中所有的内容包括imageCache还用所有的message都是需要存储到持久化的chrome.storage.local中,如果想要加载更快,那么就必须把所有的图片b64url从会话记录中剔除出来。
我的方案是,两层存储,剔除b64url的messages是一层,替换成一个特殊标识,例如session_store:ref1,然后所有的图片放到另一个storage的key。加载的时候,同步加载messages也就是第一层的内容,因为全都是不含b64的文本内容会非常快。然后加载完成后,异步的去把图片的storage加载到内存,然后把session_store:ref1这种特殊标识的地方替换回来。
从形态上讲,一份历史记录msg有四种形态:
- 1 持久化形态:chrome.storage.local中的数据,这里有两份,一份是纯base64图片的单独存储,一份是去掉b64的文本内容。
- 2 内存形态:react component中的state,从两个持久化的存储中将数据加载到内存中的,同步加载文本,异步加载图片,并且还会补充一些元数据描述,比如某一条msg的状态是水合中,水合完成。
- 3 llm请求:放到http请求中的msg,需要将内存形态转换成三种不同协议的request,有些内容要拼接补充,有些要删除等。
- 4 UI展示:react中UI展示和内存中数据是同步的,数据驱动展示,但是有一些特殊的逻辑,比如有些消息中,补充的一些字段(红字)不展示在UI中等。