最近在倒腾一些vibe coding相关的事情,主要是因为最近发现ai的编程能力越来越强了,最早用claude code感觉整体的能力还比较差,但是随着版本迭代和新模型的推出,整体的能力已经非常强大,以至于工作中的简单需求都是扔给ai去写,人来做review了。
这篇文章主要是从个人的角度去评价一下我用过的一些vibe coding工具(也包括不同的模型),以及一些经验分享。
背景
我的Vibe Coding Tool Kit是比较杂的,这分为在公司和在家两个场景。
在公司还好,公司提供了丰富的ai工具
openai,anthropic,google的主流模型在公司都有提供cursor也可以直接申请augmentcode也可以直接申请
但在家的话,情况就不一样了,受限于家境贫寒,以及vibe coding的大量token消耗,我主要的LLM访问渠道有:
OpenRouter,但是现在or上也无法调用gpt和claude了,提示是我的国家/地区不让用这些模型。当然其实能访问的话,也尽量不会用or,他的价格就是原价,比较贵。SiliconCloud,硅基流动之前有一些邀请得到了一些优惠额度,大概有500块钱的额度。但是这个额度并不能用最新最猛的一些模型,只有充钱才行,目前我主要是拿来调deepseekV3.2。- 一些转发的代理商,这种非常多,我也有三四个平台的账号,每个上面钱都不多。转发的代理商也分三六九等,我们后面再展开说这个。
OpenCode Zen,opencode号称开源版本的ClaudeCode,zen是他提供的一个转发服务,做的事情和OpenRouter一样,只不过他能转发的模型很少,但好消息是,这上面很多模型是有蜜月期免费使用的,比如现在2026-02-19MiniMax2.5Glm5这几个春节档最强国产编程模型都可以免费调用的。

augmentcode
这个插件是第一次让我我改变vibe coding认知的这么个插件,我25年上半年刚入职新公司,对项目都不是很了解,当时公司就买了这个插件,鼓励员工使用,我让这个插件帮我解释各种代码逻辑,修改代码,写单测,非常有用。节省了非常多的时间。
虽然好用,但是这个插件包括cursor对于普通人来说太贵了,一个月大概都是20美元,140块钱,还是太贵了。如果公司没有购买的话,我理解大多数人是用不起的。更适合普通人的方法,一种是拼车,比如三四个基友一起买一个订阅,这样一个人一个月大概三四十,每天也就1块钱,就还可以接受。另外一种就是直接搜咸鱼,这个就自己搜吧,感觉属于灰产。
ClaudeCode (CC)
claude code作为anthropic公司推出,也是Vibe coding第一次以系统化的工具出现的开山之作。在cc刚出来的时候,是很惊艳的。各种tool的深度集成比如bash、file读写、websearch等,这些都真正优化了vibe coding的体验。还有subagent拆分上下文等等。我最早是没觉得Vibe Coding会有多好的发展的,当时是觉得模型需要上下文,但是项目有时候太大了,很难给他提供正确合适的上下文代码,毕竟调用栈可能比较长。结果后来就比较打脸,CC通过你提供的关键词,进行搜索定位函数,然后继续搜索定位函数调用的地方,不断重复,把要修改的功能的整个链路都通过bash的grep或者rg等工具搜索到。
我经常用CC来实现工作中的依赖度比较低的需求,还有我不了解的项目某个feature是在哪段代码实现的,也可以让CC去找,定位还是很准确的。其实Ai的Coding能力我是不惊讶的,但是主要是理解和找已有的项目的关键代码的能力我之前一直抱有怀疑,但是CC证明完全没问题,而且比我自己找的效果还要好。
claude code评价一下就是大多数人的选择,各种项目表现都是不错的,如果你还没开始Vibe Coding,那么你可以赶快体验一下CC,很长一段时间都是我的主要的ai变成工具。再说到CC的缺点,因为国内无法直接调用Anthropic的接口,所以想要用Claude模型是比较麻烦的。要么用一些转发代理的渠道继续用claude模型,要么就换其他国产模型,当然这两种方式都需要修改配置文件。
简单介绍下如何修改,有一些开源的工具可以帮你修改配置文件,比如ccswith ccman之类的,可以自己搜一下,他们不仅可以改CC还能改codex等。
如果要自己修改的话,CC的配置文件在~/.claude/settings.json,不同操作系统的目录都是这个。这个文件的格式如下:
{
"env": {
"ANTHROPIC_BASE_URL": "https://api.siliconflow.cn",
"ANTHROPIC_AUTH_TOKEN": "sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx",
"ANTHROPIC_MODEL": "deepseek-ai/DeepSeek-V3.2",
"ANTHROPIC_DEFAULT_HAIKU_MODEL": "deepseek-ai/DeepSeek-V3.2",
"CLAUDE_CODE_DISABLE_NONESSENTIAL_TRAFFIC": "1",
"CLAUDE_CODE_MAX_OUTPUT_TOKENS": "32000"
},
"permissions": {
"allow": [],
"deny": []
},
"alwaysThinkingEnabled": true
}
这里主要是通过一些env环境变量来指定的,其中如果要修改为第三方模型主要是要修改ANTHROPIC_BASE_URL, ANTHROPIC_AUTH_TOKEN, ANTHROPIC_MODEL。另外还需要保证你的这个第三方的模型供应商是有/messages接口的,因为CC是按照自家anthropic的接口来调用的,如果你的供应商只提供了/chat/completions接口(这是openai的接口规范),那么是不能通过修改配置的方式来实现的,还需要一层接口转换层。好消息是现在大多数供应商都同时提供chat/completions和messages接口形式。
如果你的供应商就正好仅提供chat/completions接口,那么你可以删掉上面的env配置,安装claude-code-router这个开源项目,然后根据项目说明用它来配置转换即可。
另外评价一下模型,其实我一直是claude-sonnet模型的用户,从claude-sonnet-3.5开始就没有切换到GPT系列模型用过,直到gpt-5.2-codex,当然这是后话。整体我觉得claude-sonnet系列模型的编程能力一直在最高水准一档。
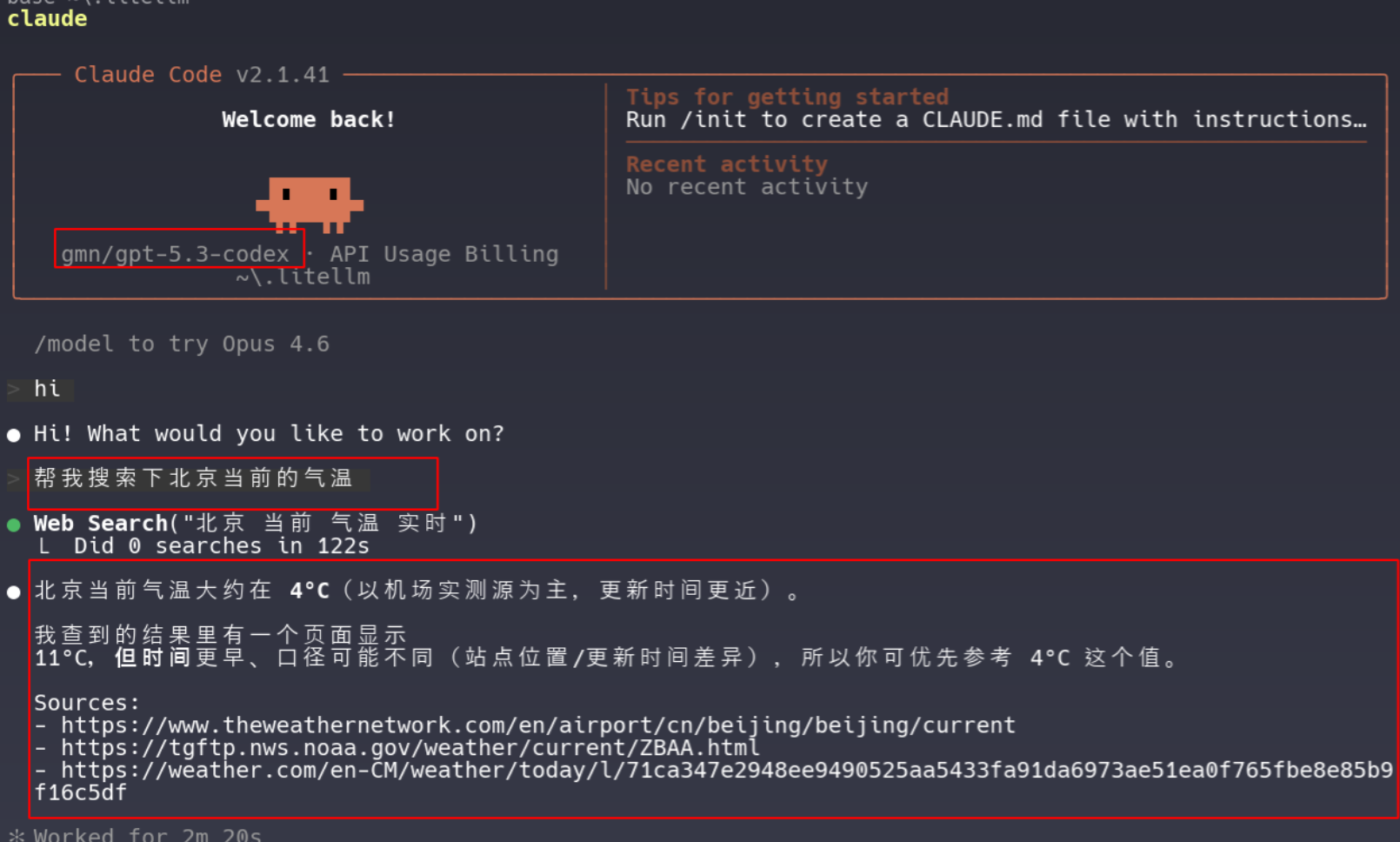
我现在的用法是CC + claude-sonnet,我相信原配肯定是最好的。在公司就用公司提供的额度,在家里的话没有办法,只能用一些转发平台,转发平台便宜很多,但是这些转发平台,大都采用一些逆向技术,分析了某些app提供的优惠码或者套餐之类的,然后自己注册很多这种app的新号,形成一个池子,然后将客户的请求模拟成这些新号从app中发起的请求,算是灰产,但起码真的是claude模型。这些国内的转发平台,很多不支持内建的工具调用,例如WebSearch WebFetch,最简单的验证方式是,你配好之后打开cc,问一句“帮我搜索一下当前北京的气温”。看他能不能正常去网络上搜索。
这里我个人感觉web搜索的能力是很重要的,我的案例也有不少:
- 1 公司用了一个比较冷门的测试框架
karate,这时候有些特殊的改动是需要到他的官网去搜索如何写的。 - 2 我在研究大模型的openai的
chat/completions和anthropic的/messages接口的区别,这时候需要到他们的官网去搜索文档,以及还想要对比openrouter和litellm对参数的兼容,这些也需要搜索文档。
总之对于一些变更比较频繁,或者一些比较新的技术,web搜索能力是很重要的。
题外话:
这时候有人会说function calling的执行者不都是本地吗,这和模型的能力有什么关系?正常来说是本地提供一个名为web_search的函数,大模型判断要触发这个函数,返回给客户端参数,客户端调用一个搜索的函数。但是去年开始openai和anthropic开始提供内建的tools,主要就包括了websearch等几个。也就是搜索这个能力,在服务端集成了,这就简化了搜索的流程,不再需要2轮对话,而是1轮对话,server端发现要触发search,自己就触发,然后拿回结果进行汇总,一次性返回响应了。
如果你购买了某个转发的服务,你不妨在claude code中进行一下上面的测试,如果能正常进行搜索,那么这个转发平台就是真转发,好平台,如果报错不支持,那么就是比较差的。整个流程可以进行抓包观察的,如下:
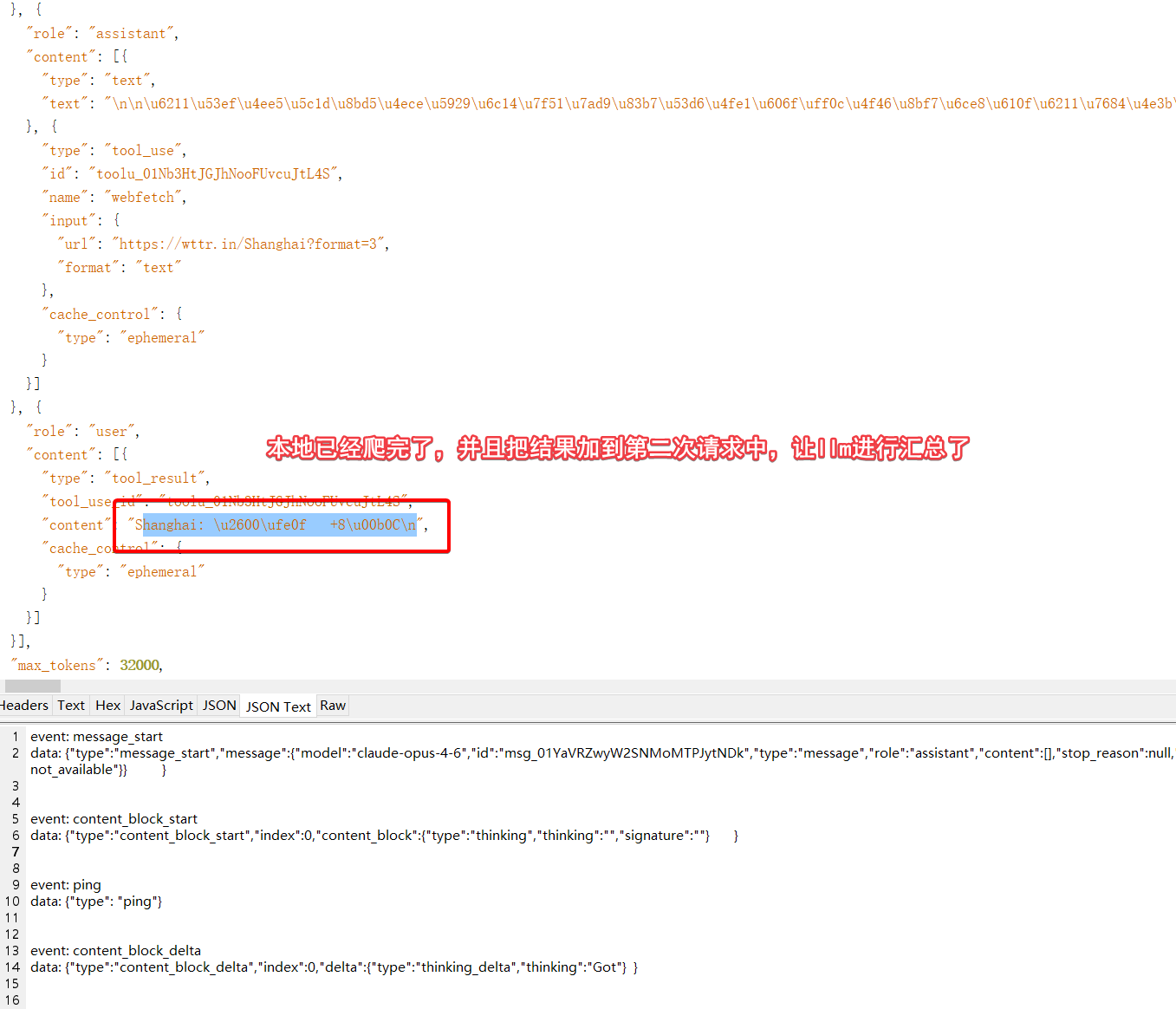
第一个请求会触发本地一个WebSearch搜索函数,什么,本地?没错,这是CC封装的本地函数。刚才不是说Server端的内建web_search吗?别急,继续看下一个请求。
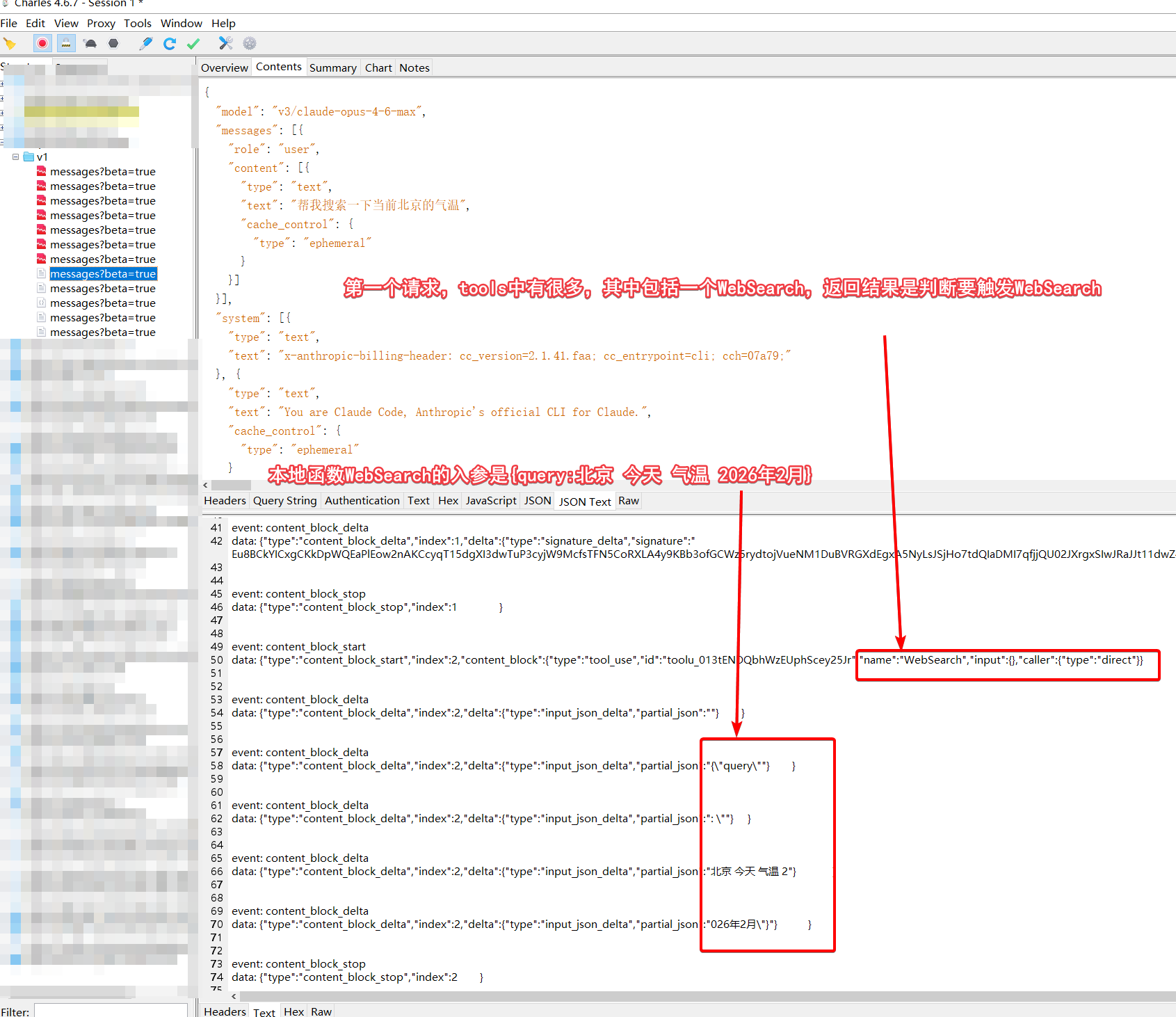
第二个请求是subagent发起的,默认这个agent应该是用haiku小模型触发即可,但是这里我都指定了一个模型,他的结果如下,可以看出我这个转发平台是比较靠谱的。
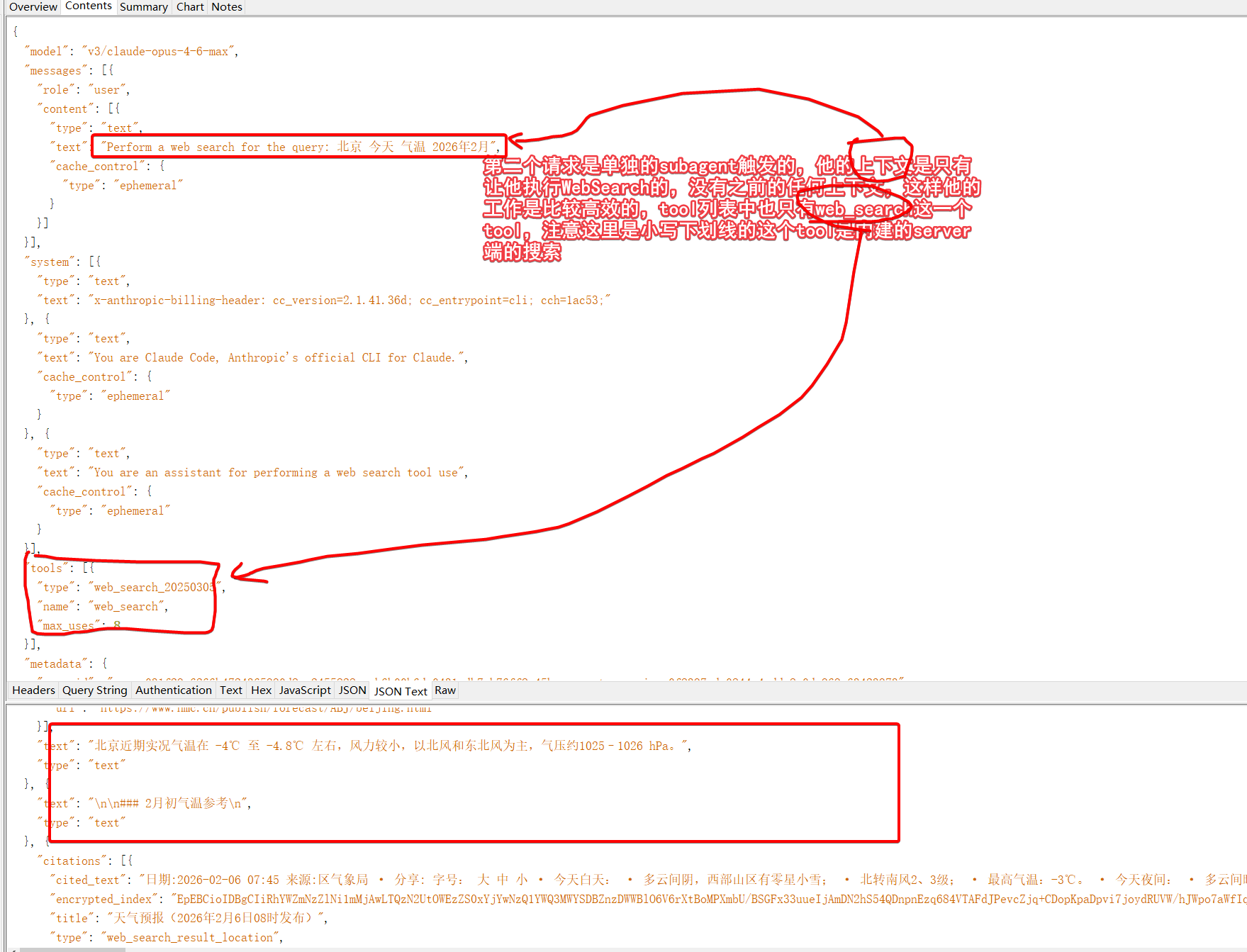
最终CC页面的效果是这样的:

WebSearch和WebFetch是两个独立的tool上面的调用过程中实际上只用到了内建的websearch,而后续的webFetch是本地执行的,我没有抓包到WebFetch的LLM请求。从这篇文章的分析可知CC的WebFetch确实没有用自家的内建工具,而是本地发起的,而本地发起的流程中还需要到claude.ai去校验域名是否安全,而这一步在国内,如果没有配置代理会被墙,如下。

哦,对了这种抓包的方式,可以很好的观察工具和llm的行为。之前有视频和文章都讲过,这里额外提一句的是,如果默认的OS proxy开启,抓不到包,那可能需要你单独配置一下环境变量。
# 8888 charles proxy port
$ export HTTPS_PROXY=http://127.0.0.1:8888
# 这个pem是charles,help->SSL proxying->Save Charles Root Certificate保存的证书
$ export NODE_EXTRA_CA_CERTS = "C:\Users\sunwu\Desktop\code.pem"
# 启动claude就可以在charles上看到抓包数据了
$ claude
如果要抓litellm的包,这是python程序,那么设置如下环境变量。
# 8888 charles proxy port
$ export HTTPS_PROXY=http://127.0.0.1:8888
$ export REQUESTS_CA_BUNDLE = "C:\Users\sunwu\Desktop\code.pem"
$ export SSL_CERT_FILE = "C:\Users\sunwu\Desktop\code.pem"
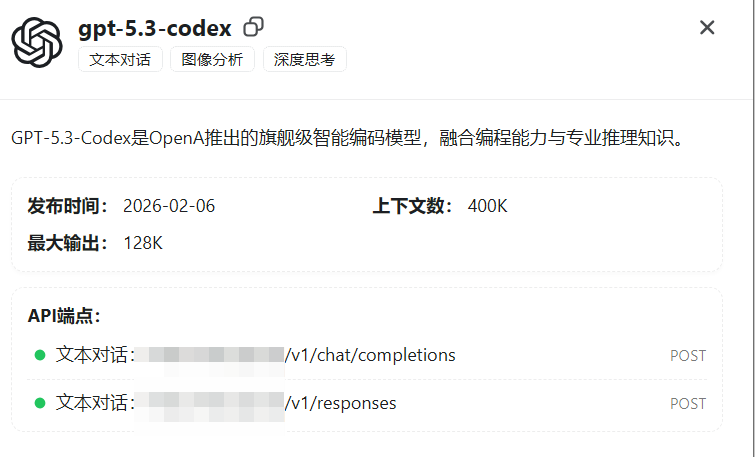
Codex
codex是openai推出的与claudecode竞争的产品,openai的产品策略还不止是和cc对齐,在openai官网已经把codex列为专门的产品,看上去要更重视一些。甚至推出了新的模型gpt-5.1-codex gpt-5.2-codex 以及gpt-5.3-codex。甚至gpt-5.3-codex目前还没有开放api访问。我对gpt的态度一直都是比较通用,但是在编程上还是claude更强,但是gpt-5.2-codex让我改变了想法。
之前有一个简单的demo的页面+后端接口的设计实现,分别交给CC+claude-sonnet-4.5,codex+gpt-5.2-codex和gemini-cli+gemini-2.5-pro实现,然后我发现gemini组合的bug太多了,虽然后续一直让他修复,最终也是一个可用的状态,但是一次性交付能力比较差,而且页面设计的也一般(我忘了在哪看的说gemini前端设计很好——我是完全没感觉到,可能是偶发?)。CC的功能一次性交付了,但是整体页面样式非常普通,有点像早年bootstrap,另外就是有一些细节做的不是很好,后续让他改进也完成的不错。而codex组合让我眼前一亮,首先是页面样式设计的非常美观,更重要的是细节,codex对细节的把控非常好,加了很多小提示,切换的时候动画的流畅上也有专门的设计。当然这一个案例其实并不能说明什么,但是足够让我先把gemini给淘汰掉吧。
此后我也开始大量使用codex,他确实也惊艳到我很多次,我给这个模型的关键描述就是细节,细节怪。我还用codex做了以下事情:
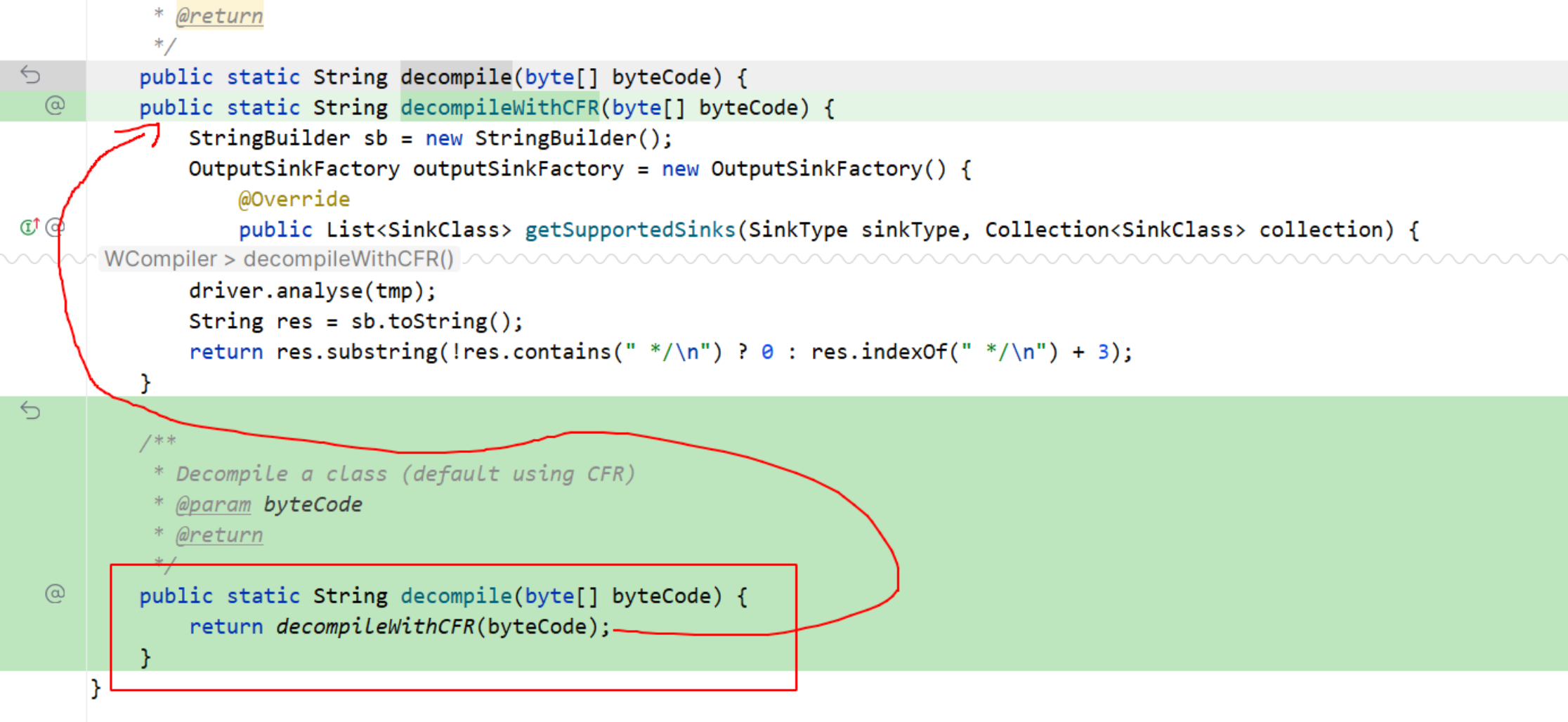
1 把jetbrains的java反编译工具fernflower改成java8语法了,codex用了大概两个小时,将所有的代码都改成了java8总计2k行作用。中间有个改动有bug,导致单测无法通过,他自行分析代码,添加了一些日志和新的单测,最终找到了问题并修复了。要知道这个任务,我是先用的CC + glm4.7做的,完全做不了,写到一般就问题原来越多,以至于无法收敛,最终自己放弃了。这是codex最终给的改动,repo,我也用这个repo的jar包更新了我另外一个swapper项目中的反编译功能,废弃了CFR改为用这个库了(之前是因为它是java21的望而却步)。
2 调研并写一个AI三种接口规范的demo演示页面chat/completions messages responses,效果非常好,甚至看到页面的时候我自己都没想到一些细节,比如我在需求描述里面有写要对比下不同接口的内建web_search的写法,然后我的endpoint用的是openrouter,结果他还调研了openrouter发现网关层本来也有个plugins可以添加WebSearch的能力,把这个也加到功能开关之一了。
3 让codex帮我写一个反向代理openrouter这个代理的代理服务,背景是openrouter上用不了claude如下图,需要用VPN,这样非常麻烦,所以想到写个cloudflare的worker,把所有请求都转发到openrouter,然后worker指定只在美国部署。
这是codex给我的结果repo,我没写过一行代码,包括前面几个也是,我就在刷哔站视频,然后看他干活,效果就是他给整个openrouter代理了,我也可以在国内通过这个代理访问or的claude gpt模型了(虽然是原价,但是是正宗的渠道)。
4 让codex帮我分析为什么litellm无法配置下游只有responses接口的供应商,结果他直接下载了litellm源码,然后定位到是可以的,要在model配置的时候添加openai/responses/前缀,并把对应代码给我展示。我配上之后果然好使,然后我又想让CC中能用responses接口,这还需要一个改动是怎么把上面提到的websearch做兼容,因为openai和anthropic都支持WebSearch但是在入参中的定义方式是不同的,codex帮我修改了请求转换器把这个转换完成了,最终我能在CC中使用repsonses接口的gpt-5.3-codex模型,并且支持web_search web_fetch工具了(openai只有web_search,实际上要把antropic的search+fetch 都映射成openai的search
)。
codex如果要修改成第三方模型的话,也可以用CCswitch等工具,自己修改的话需要修改配置文件~/.codex/config.toml,其格式如下:
model = "gpt-5.3-codex"
model_reasoning_effort = "xhigh"
disable_response_storage = true
sandbox_mode = "danger-full-access"
windows_wsl_setup_acknowledged = true
approval_policy = "never"
profile = "auto-max"
file_opener = "vscode"
model_provider = "gmn"
# web_search = "cached"
suppress_unstable_features_warning = true
[history]
persistence = "save-all"
[tui]
notifications = true
[shell_environment_policy]
inherit = "all"
ignore_default_excludes = false
[sandbox_workspace_write]
network_access = true
[features]
plan_tool = true
apply_patch_freeform = true
view_image_tool = true
unified_exec = false
streamable_shell = false
rmcp_client = true
elevated_windows_sandbox = true
[profiles.auto-max]
approval_policy = "never"
sandbox_mode = "workspace-write"
[profiles.review]
approval_policy = "on-request"
sandbox_mode = "workspace-write"
[notice]
hide_gpt5_1_migration_prompt = true
[model_providers.gmn]
name = "gmn"
base_url = "<your_base_url>"
wire_api = "responses"
requires_openai_auth = true
这里需要你修改上面model和base_url,然后修改同一目录下的auth.json
{
"OPENAI_API_KEY": "sk-xxxxxx"
}
codex比较坑的是现在的版本已经不再支持wire_api=chat了,说人话就是不再支持自家的chat/completions接口了,只支持responses这个接口,大多数供应商都没有支持这个去年3月推出的规范,好像就openai自己在固执的使用这个接口,这个有点难绷,如果要购买一些提供gpt模型平台的额度的话,可以看下gpt这些模型支持的endpoint是否有responses如下。
codex相比cc,其他的几个优势,codex开源,CC闭源; codex有个mac版本的app; codex还有沙盒环境并行开发。
OpenCode
前提:我个人感觉工具之间的差距不是很大,比如让cc和codex同时都用同一个模型,得到的效果差距不会太大。毕竟大家都是抄来抄去。你加了个什么tool我也会加一个。所以OpenCode作为一个号称开源版本的ClaudeCode,很受欢迎就是理所当然的了。据说是逆向分析了CC在各个场景下发送的数据包,就像前面介绍web_search我进行的抓包一样,然后根据抓包的内容就知道了,不同场景的提示词。然后稍微改吧改吧,就整合出了开源版本的CC,早期应该还有另外几个“开源版CC”,但是OpenCode团队在各方面都做的最好,所以就成为活下来的那一个了。所以我认为那些对比OpenCode vs ClaudeCode,用相同的模型,还能对比出巨大差异的,都是扯淡。
有了上面这层理解,再来审视OpenCode这个工具,思路就清晰了。OpenCode的接入使用可以说是最友好的,刚启动或者/connect就可以选择很多家供应商,然后配置key和选择模型。
如果你是代理供应商不在这里面,你还可以修改一下~/.config/opencode/opencode.json这个配置文件,来增加供应商,如下是我增加了一个本地的litellm服务的配置。
{
"$schema": "https://opencode.ai/config.json",
"provider": {
"litellm": {
"npm": "@ai-sdk/openai-compatible",
"name": "LiteLLM",
"options": {
"baseURL": "http://localhost:6043/v1"
},
"models": {
"v3/gpt-5.3-codex": {
"name": "v3/gpt-5.3-codex"
},
"v3/claude-opus-4-6-max": {
"name": "v3/claude-opus-4-6-max"
},
"gmn/gpt-5.3-codex": {
"name": "gmn/gpt-5.3-codex"
}
}
}
}
}
这里还是围绕前面说的websearch webfetch来说一下OpenCode与其他两个工具的不同,我们前面说的这个网页能力被openai/Anthropic集成到server端了,他们出的工具CC/codex也就用了server端搜索的能力。但是OpenCode要考虑的是各个供应商的不同的模型,所以对于搜索功能给出的实现是本地的搜索。
如下,我分别用支持claude-opus-4-6-max和deepseek进行了web搜索,他们都是能做到的。
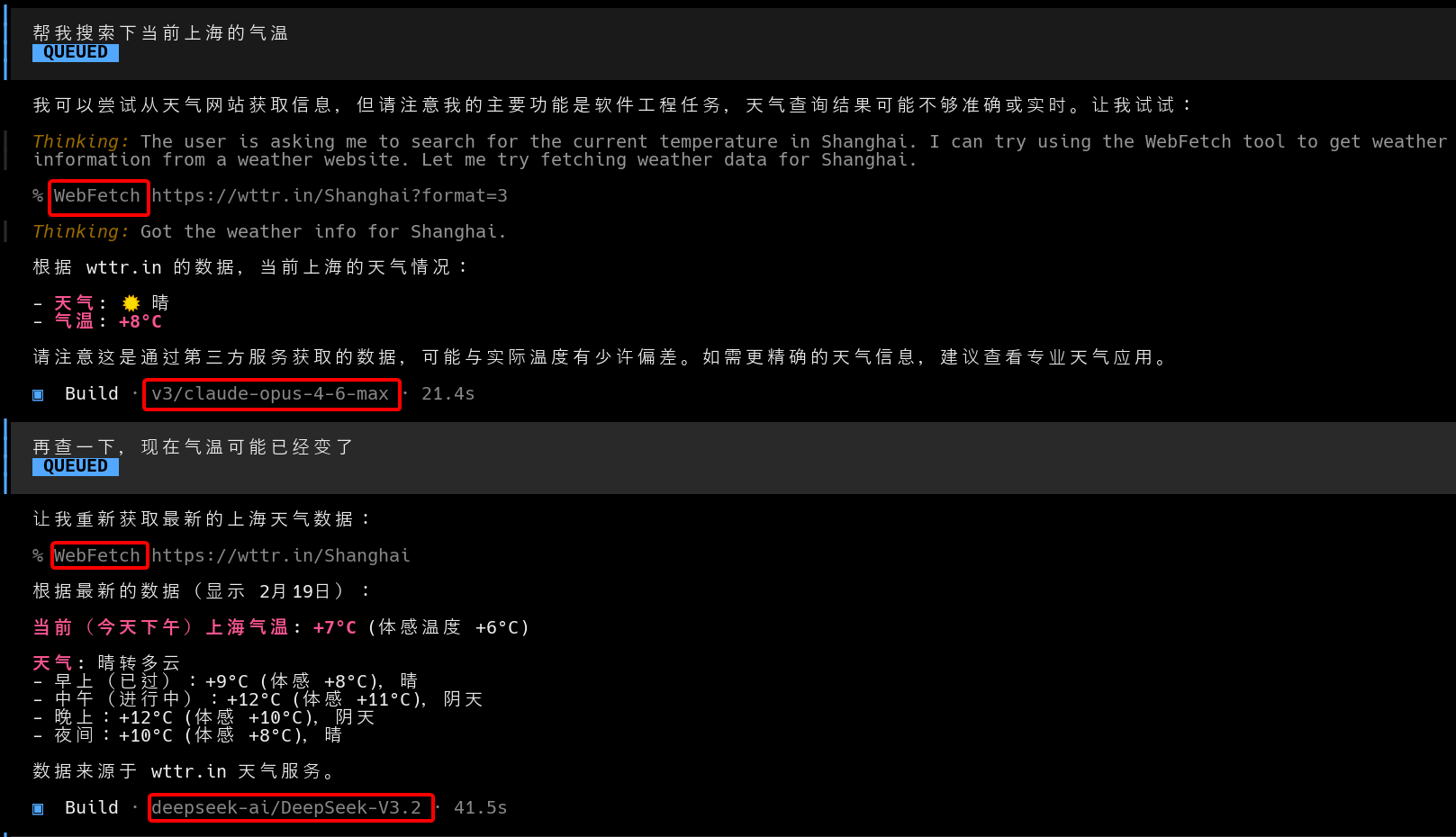
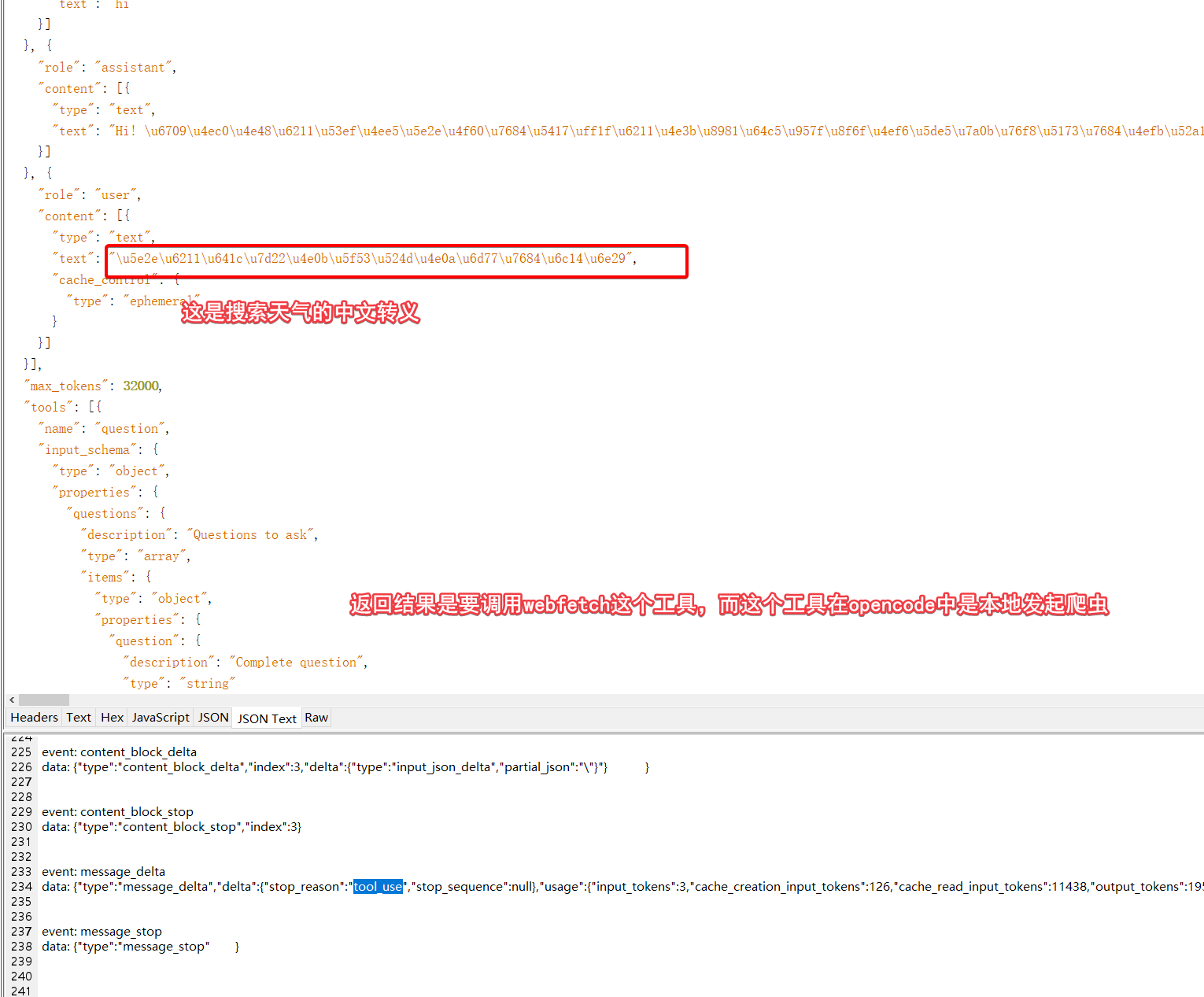
这里的搜索工具还是像之前一样,用两轮对话的方式,本地发起查询。这样对大多数模型供应商的兼容性更好,当然也会有另外一个问题,就是如果有时候要搜索一些框架或者文档,比如claude的官方文档,用中国的ip就看不了。还有一些会很慢,比如spring官方文档的页面等,甚至有时候国内访问github都超时,如下图。总之有利有弊吧。

另外值得一提的是OpenCode有个OhMyOpenCode(OMO)插件,默认配置了多个agent来完成不同类型的任务,由一个管家agent调度多个subagent而不同的subsagent可以配置不同的模型。另外OMO会帮忙安装一些MCP工具,其中就有WebSearch(基于https://mcp.exa.ai/mcp),原来OpenCode只有WebFetch功能,需要模型直接按照经验给出要访问的URL才行,而有了WebSearch可以先搜索信息,再找到对应的网址,这样信息更准确。额外再强调一下openai的websearch是集合了websearch webfetch grep三合一的功能。
下面是三种cli进行网页搜索和爬取的流程对比:



对于OMO我的态度比较激进,是不太想配,因为我没有订阅很多的模型,而且我的模型渠道都很杂,搞不好就要换,所以需要经常该这些模型,而OMO的一堆子agent要分别配置各种模型。实在是有点麻烦,当然第一次配好了可以用一段时间,等新模型出来,或者渠道变了,我又得来挨个改配置。所以我目前是不怎么用OMO的,上面OMO添加的WebSearch/Context7等MCP可以自己手动添加的。
自定义webfetch
其实我们可以自定义一个webfetch的MCPserver,部署到cloudflare上,然后给claude code把这个mcp配置上,然后在~/.claude/GLOBAL.md里面加一句优先使用MCP中的webfetch来进行网页内容获取之类的话。
不过cf部署完之后,有点小问题,就是无法访问谷歌,会报错429,因为谷歌给cf这些节点ip都拉黑了,另外cf需要域名才能访问,否则国内还是访问不了。那么还有什么其他候选吗?有的,兄弟,有的。条件是免费,serverless,那render netlify vercel railway都是可以的,但是这些要么基于容器技术,启动较慢,长时间没有请求后,第一个请求需要将近1分钟。要么有的还被墙。
考虑到响应速度要快,要么就是常驻服务(基本得花钱),要么就是V8或wasm的运行时,cf就是自研的v8运行时。而除了cf之外,还有一个选择,就是非常冷门的deno deploy平台,(deno也不行了,不允许网络转发类型的服务,我的应用已经被封了),我最近还发现他们竟然还发布了新版的系统,正好用上了。可以看这个项目:deno-webfetch-mcp(这个项目已经被封了),里面介绍了配置CC的方式,基本就是一行指令加个mcp server,然后修改GLOBAL.md优先使用mcp WebSearch就可以了,
上面的deno-webfetch-mcp项目已经被官方强制下线,因为deno的用户准则里明确不允许代理类型的服务,然后我发现netlify没有禁止。所以把这个mcp转到netlify平台了,同时增加了搜索的能力(通过brave search和duckduckgo),放到一个新的项目下了orz-mcp,同时提供了stdio和http两种模式,任选一种即可。
供应商
因为国内这个环境的问题,我们就不说openai anthropic google等这些条件苛刻的官方渠道了。
能够正规访问到gpt/claude模型的供应商就是openrouter,价格也是官方的价格,但是比较坑的就是去年下半年的时候,他也加了地区判断,中国的ip无法访问gpt/claude等模型,其他没有地区政策的模型还是正常访问的。所以这也就是为啥上面,我提到让codex帮我写了个openrouter的代理服务了。靠这个代理服务就可以正常访问了。
各种转发平台,我现在手头有个四五个转发平台,价格波动也比较大,比如有个转发平台他同一个模型有多个分组,其实是不同的渠道,有的是逆向,有的是官转。如果是官方转的渠道,他基本就是原价。而如果是逆向的,他又不支持web_search这些功能。对于逆向渠道会便宜不少,大概便宜5到15倍,取决于逆向渠道,我个人就是看手里这几个哪个模型便宜,就用哪个,因为不同模型在不同平台,细算下来又有差异。
最后我将各个不同的供应商和他们支持的自己会用到的模型,配置到本地的litellm中,这样相当于自己做了一个网关汇总,就不需要每个应用里面再去单独配置各个供应商了。
总之不差钱的富哥就用openrouter原价吧,如果是vibecoding的话,算上prompt cache我觉得一天也就两三刀,(我是指在家自己用的项目,工作要每天都用的话不止这个数)大概十几块钱,一个月的话估计也就用个10来天,算下来一百多,好像和开会员差不多了,但是突出一个随用随付,没有心理负担。如果是家境贫寒,那我建议直接用opencode + zen提供的免费模型,一条龙给你安排明白了,而且免费的模型还真不差glm5 minimax都是国产巅峰了。如果心有不甘还想用claude这些模型的,那就搜一搜中转的平台,货比三家,少充点对比下价格倍率,和支持的功能(建议测下是否支持WebSearch)。然后咸鱼搜一搜有没有渠道,以及看看搭伙能不能几个人共用plus之类的。
锐评
三个cli工具的对比CC, Codex, OpenCode,从能力上我觉得差距是不大的。从页面美观上,OpenCode要更好一些,尤其是在Windows环境下。另外就是查询最新信息的web功能上,如果是国外用户,那这三个工具都没有问题,但是如果是国内用户,网页在哪里发起的访问,是否能访问就是一个绕不开的问题。(原谅我全篇都在关注web的扩展,因为我写很多东西真的需要依赖上网的功能)如果考虑到websearch webfetch的兼容性,那我觉得满血的codex + gpt-codex转发,在国内是最友好的,这也成为了我目前在家环境的主要开发方式。因为所有网页访问都是委托给llm供应商来完成的,供应商其实最终是转发到了openai,他是可以无墙访问github google等等各种技术网站的。当然如果你配置个HTTPS_PROXY环境变量,然后启动CC也没问题,只是如果是渠道代理的可能会有chat请求多绕几圈的问题。codex的坑在于,新版本只支持responses这个非主流接口了,除了openai很少有其他供应商做这个接口的兼容,所以如果你用的不是gpt模型,没有responses接口的话,那我建议放弃codex吧,不然还要找转换工具。
模型的对比,从编程能力上,opus-4.6和codex-5.3应该是第一档的,不论是实际用下来的效果还是网上的benchmark都是这样,gemini的话,一直说他的前端能力很强,这个我的体验不是很明显,可能我审美太拉了。另外是国内的模型MiniMax Glm5 Kimi2.5这几组效果也不错,对于普通的需求是够用的,属于第二档了。我的体感就是,国内模型在编程细节上还有待提升,另外就是没有“匠心”精神,之前有个让glm把我的反编译的工具从cfr改成其他的,结果给我好几个方案,然后我说随便哪个只要实现就行,结果写了一个多小时,消耗了我20块钱的token,最后什么也没干,把改动都回滚了,然后给出如下答卷(心态崩了)。
从模型价格上对比,因为vibe coding是非常消耗token的,所以价格也是一个重要的参考项。以下价格均来自openrouter平台,如果在各自平台有订阅,或者特殊供应商有优惠,价格也会有波动,这里主要是个参考。
claude-opus-4.6I/O/W $5/M $25/M $10/kclaude-sonnet-4.6I/O/W $3/M $15/M $10/kgpt-5.2-codexI/O/W $1.75/M $14/M $10/kgemini-3.1-pro-previewI/O $2/M $12/M
相比之下,国产模型在价格上的优势巨大:
qwen-3.5-plusI/O $0.4/M $2.4/Mminimax-2.5I/O $0.3/M $2.1/Mglm5I/O $0.3/M $2.55/Mkimi2.5I/O $0.23/M $3/M