AI API Schema
本文整理一下AI接口的请求和响应的schema,主要基于openai和anthropic的接口,以及路由型应用开源的litellm和openrouter对参数的适配与转换。
1 completions
llm的接口主要是chat接口,追溯历史的话可以从/completions接口开始,这个接口规范主要应用于gpt3以及之前的模型,并且从2023年开始已经不再更新,官方文档,这个接口的参数和返回值和他的继任者/chat/completions类似,最大的区别是入参中的prompt,prompt是一个大的长纯文本,如果进行交互的话,历史记录要一直作为纯文本追加到这个字段中,后来的/chat/completions接口就是对这个接口的增强,把prompt参数改为了messages,而messages参数是一个数组,后面会介绍。
{
"model": "gpt-3.5-turbo",
"prompt": "Hello, how are you?"
}
completions接口的响应格式也和/chat/completions类似:
{
"choices": [
{
"finish_reason": "length",
"index": 0,
"logprobs": null,
"text": "\n\n\"Let Your Sweet Tooth Run Wild at Our Creamy Ice Cream Shack"
}
],
"created": 1683130927,
"id": "cmpl-7C9Wxi9Du4j1lQjdjhxBlO22M61LD",
"model": "gpt-3.5-turbo-instruct",
"object": "text_completion",
"usage": {
"completion_tokens": 16,
"prompt_tokens": 10,
"total_tokens": 26
}
}
这个响应是一个对象,其中choices是一个数组,响应格式与/chat/completions的响应格式是类似的,一般从choices[0].text取出返回的回答。
因为是个老的接口,现在基本已经不会使用了,这里就不展开介绍了。
2 chat/completions
chat/completions接口是GPT3.5之后一直在使用,并且也间接形成了LLM接口的规范,现在大多数模型供应商都是按照这个接口的形式在使用,这是官方文档
我们从请求参数开始介绍,默认至少要有两个必传字段,model和messages:
{
"model": "gpt-3.5-turbo",
"messages": [
{
"role": "user",
"content": "Hello, how are you?"
}
]
}
messages中role最早有三个基本的取值:system(表示系统设定),user(用户问的问题),assistant(模型生成的回答),后来扩展了developer(开发者替换了system),function,tool(这两个与函数调用相关,后面展开)。
除了model和messages,这个接口的入参还有非常多的参数.
有很多是不太需要修改的,比如大模型的采样相关的一些参数,比如:
frequency_penalty(-2,2)为了降低早期模型一直重复一行文字的概率的,现在很少有这个问题了。logit_bias(map)降低特定token出现概率的,大多数业务场景不会用到。logprobs(int)是否返回每个token的概率,大多数业务场景不会用到。top_logprobs(0,20)必须logprobs为true才有效,返回每个位置前topk个token,大多数业务场景不会用到。presence_penalty(-2,2)对已有的内容惩罚,主要是为了让模型能更多或更少讨论新话题用的(发散性),大多数业务场景不会用到。store是否存储历史记录,大多数场景都是false,一般不会让服务端存储这个历史记录。safety_identifier用来标识用户,当请求出现违反安全策略的时候,可以追溯到是哪个用户的。
还有一些参数是比较重要且常见:
temperature(0,2)温度(发散性),越高越多样化,越有创造性,也越不聚焦。top_p(0,1)概率采样,与temperature的作用结果类似,两者选择一种。stream是否返回流式响应,现在多数场景都是需要流式相应的。max_completion_tokens最多能用多少token回答,主要用来限制回答长度,成本控制等。(Deprecated)max_tokens改成max_completion_tokens了。n(1,128)返回结果的数量,大多数业务场景都是1。verbosity:(low/medium/high) 啰嗦程度。
缓存相关的,这个是openai的辅助服务非基础模型参数,如果是其他供应商可能没有:
prompt_cache_keyopenai的提示词缓存分了256个分片,相同的key会在相同分片中查询,所以加了这个可以提高缓存命中率的。prompt_cache_retention(in_memory/24h) 保留时长,
工具(函数调用)相关的:
tools告诉llm可用的工具有哪些,这是个数组。type(function/custom),function就是最基础的用户自定义函数,需要给出各个参数的定义等信息;custom则是对前者的简化,默认接受一个字符串,返回一个指令字符串,则这个函数直接作为入参去执行,文档。function: 如果type是function类型,这个字段是函数的定义{ name, description, parameters, strict }custom: 如果type是custom类型,{ name, description, format }
tool_choice("none" or "auto" or "required")是否可以选择使用工具,保持默认即可。parallel_tool_calls(boolean)是否可以在一个response中返回多个函数调用,可以避免或允许同时调用多个函数。web_search_options,内建工具websearch专门的一个参数配置。(Deprecated)functions改成tools了。(Deprecated)function_call改成tool_choice了。
多模态相关的:
modalities: (text/audio)返回文本还是音频。audio如果返回是音频结果的话,对于音频的一些约束format: wav, mp3, flac, opus, or pcm16.voice: openai内置的几个人名的声音。
其他:
response_format: 现在主要用来指定回答按照json格式返回,便于业务中直接做结构化处理。reasoning_effort(none/minimal/low/medium/high/xhigh):思考推理的强度,特定模型有用。
而对于response基本格式如下,其他字段不需要解释,核心的内容在choices中:
{
"id": "chatcmpl-B9MBs8CjcvOU2jLn4n570S5qMJKcT",
"object": "chat.completion",
"created": 1741569952,
"model": "gpt-4.1-2025-04-14",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "Hello! How can I assist you today?",
"refusal": null,
"annotations": []
},
"logprobs": null,
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 19,
"completion_tokens": 10,
"total_tokens": 29,
"prompt_tokens_details": {
"cached_tokens": 0,
"audio_tokens": 0
},
"completion_tokens_details": {
"reasoning_tokens": 0,
"audio_tokens": 0,
"accepted_prediction_tokens": 0,
"rejected_prediction_tokens": 0
}
},
"service_tier": "default"
}
choices中字段的其他取值介绍:
finish_reason:完成原因,可能是stop,length,content_filter,function_call(废弃),tool_calls。message.tool_calls:如果是函数调用,则这个字段会有值,其中包含了函数调用的函数名,参数等信息,现在这是个数组,一个回答可以有多个函数调用触发,与请求中parallel_tool_calls对应。
小结:
在chat/completions定义中,我们看到有很多通用基础的参数model messages temperature stream tools等等,这些基础的参数在其他供应商也被沿用,但是openai在自己接口中也夹杂了很多私货,比如web_search_options prompt_cache_key等等,这些都是他自己的定制化的参数,其他厂商很难直接复用。
3 messages
与claude模型所在的anthropic公司提供的大模型交互接口,有很多参数和chat/completions是类似的。
例如最基础的请求,其中model和messages与chat/completions是一致的,只不过role只有user/assistant两种。
{
"model": "claude-opus-4-6",
"max_tokens": 1024,
"messages": [
{
"role": "user",
"content": "Hello, how are you?"
}
]
}
另外上面的max_tokens是必传参数,这和chat/completions中的max_completion_tokens参数效果一样,openai的max_tokens改名之后,这个字段名和是否必须成为两个api最主要的入参区别。
类似的参数:
stream是否返回流式响应,现在多数场景都是需要流式相应的。temperature(0,1) 与gpt的类似,但是取值是0到1system字符串数组,类似于chat/completions中的messages.type=developer,但是只能有一个。top_p与openai的同名参数一致,并且还有个top_k参数,都是用来控制模型生成的。thinking与reasoning_effort类似,控制思考的。tools和tool_choice与chat/completions中的类似但是字段稍有不同,具体参考下面。
tools中item对比chat/completions的常见形式如下:
{
"type": "function",
"name": "get_horoscope",
"description": "Get today's horoscope for an astrological sign.",
"parameters": {
"type": "object",
"properties": {
"sign": {
"type": "string",
"description": "An astrological sign like Taurus or Aquarius",
},
},
"required": ["sign"],
},
}
而messages则如下,参数用input_schema来描述,这是主要的不同。
{
"name": "get_stock_price",
"description": "Get the current stock price for a given ticker symbol.",
"input_schema": {
"type": "object",
"properties": {
"ticker": {
"type": "string",
"description": "The stock ticker symbol, e.g. AAPL for Apple Inc."
}
},
"required": ["ticker"]
}
}
tool_choice也略有不同,completions中是字符串,messages中是对象{type: auto, disable_parallel_tool_use: false},等于是completions中的tool_choice参数 + parallel_tool_calls参数。
小结:
messages接口大部分和chat/completions参数是一致的,总体参数个数要少一些,对于一些

4 responses
为了更好的适应agent时代,openai在2025-03月的时候提出了新的接口格式responses。他的最简化的参数形式如下:
{
"model": "gpt-4.1",
"input": "Tell me a three sentence bedtime story about a unicorn."
}
和之前相比,主要是messages字段改成了input字段,这里是字符串类型,input也可以是数组类型,这样就和原来messages功能对齐了,如下就是codex使用responses接口的例子:
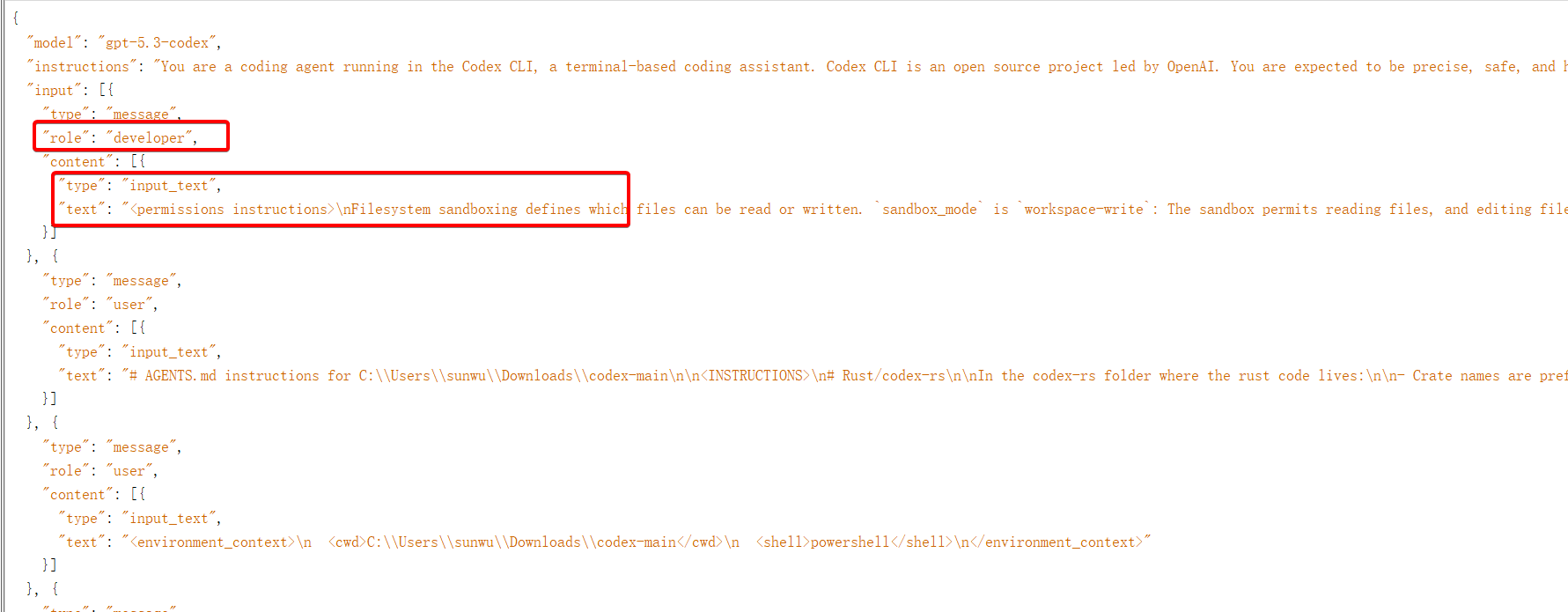
其他的大多数参数都沿用了,例如model, stream, store, temporature, max_output_tokens, tools, tool_choice, parallel_tool_calls, prompt_cache_key, prompt_cache_retention, reasoning, safety_identifier, service_tier, top_logprobs, top_p等等。
responses接口中的主要改动,是新加了一些字段:
instructions也是其实就是developer或者system类型的input,单独提出来放到这个字段中了,类似messages中system字段。background(boolean)是否允许异步在后台运行,会返回一个id,之后用/responses/id去查询,注意!!store需要为true,参考,个人感觉这个是个应用层的功能,客户端完全可以自己用一个单独的后台线程来实现这个操作,而避免把数据让openai存储。context_management{type, compact_threshold},type目前只能为compaction,compact_threshold是压缩的阈值,如果超过这个阈值,就会对上下文进行压缩。个人感觉这也是个应用层的功能,客户端也可以自己实现这个操作,在context达到阈值之后,自己单独调用一次接口进行压缩。conversation会话id,这个和openai的conversation接口相关,可以让openai管理会话,后续还可以查询或者继续会话内容,但是个人感觉这样严重依赖了openai的服务,所以就不展开了。其他供应商暂时没有会话这个复杂的实现。previous_response_id上一次响应的id,可以用来关联上一次的响应,这是一个很实用的字段,之前接口都是无状态的,每次需要把所有的历史记录放到messages/input中,而有了这个字段,每次只需要指定上一次响应的id,这样形成一个链式结构,每次只需要传当前的input就好了,历史都不需要传了。个人感觉这个功能非常实用,但是也有一些弊端,store必须为true,这对于大多数业务都不太能接受,另外其实只是让openai帮忙存储了上下文,实际的token消耗并不会变小,也导致接口成为有状态的,是一个看似很好用实际有坑的功能,在抓包codex的时候,也会发现他用的还是input数组的形式,而没有用这个字段。
这里还要单独展开说一下tools字段,responses接口中的tools进行了一些扩充,原来chat/completions中的tools是支持基础的function类型和custom类型,而这里新增了两种built-in内建工具和MCP tool,他们的主要作用都是简化Tool、Mcp的调用流程。
例如如果你有一个联网搜索的工具或者MCP,假如就是调用百度进行内容搜索,那么在之前的流程中,如果你要查询北京当前天气,那么你的步骤是:
- 1轮交互
- 调用LLM接口,请求北京当前天气,并在请求中附带
tool字段,name为search,描述是联网搜索最新的内容。 - 大模型判断这个问题需要调用你提供的
search工具,给你返回tool类型的响应内容,要调用search工具,入参是北京当前天气。 - 你本地调用了这个函数,本质可能是自己封装的查了一下百度等搜索引擎相关内容。
- 调用LLM接口,请求北京当前天气,并在请求中附带
- 2轮交互
- 将百度搜到的内容作为
tool结果,再发送给LLM - LLM汇总信息高速你北京当前的天气。
- 将百度搜到的内容作为
而内建工具的本质是函数的触发不在客户端,而在LLM服务端:
- 1轮交互
- 调用LLM接口,请求北京当前天气,并在请求中附带
tool字段,类型为内建已经支持的web_search。 - 大模型判断这个问题需要调用
web_search工具,并且因为这个type是内建的工具,所以自己直接触发进行搜索,并拿到结果,进行汇总,最后将汇总好的北京当前天气直接作为响应返回。
- 调用LLM接口,请求北京当前天气,并在请求中附带
可以看到这种交互方式是减少了一轮交互,整体的效率会更高,但是目前的内建工具只提供了
web_search联网搜索,个人感觉最通用,也是最有用的工具,在codex中你如果问搜下当前最新的nodejs版本,他就会用到这个工具,如果搜索失败,可能侧面说明你的转发的api可能是逆向的,而不是真转发。请求中是这样tools": [{"type": "web_search"}]。shell运行shell指令,这里不是在你本地运行,而是在容器中运行,请求中是这样{ "type": "shell", "environment": { "type": "container_auto" } }会临时创建一个容器基于德班系统,有一些语言开发环境,具体参考,也可以用/container接口提前创建,然后这里关联id。这里不展开了。file_search文件内容搜索,文件是多模态对话过程中已经上传的,文件上传需要建立向量存储,然后tools: [{type: file_search, vector_store_ids: [xxx] }]这样使用。- 其他的见下图,不展开介绍。
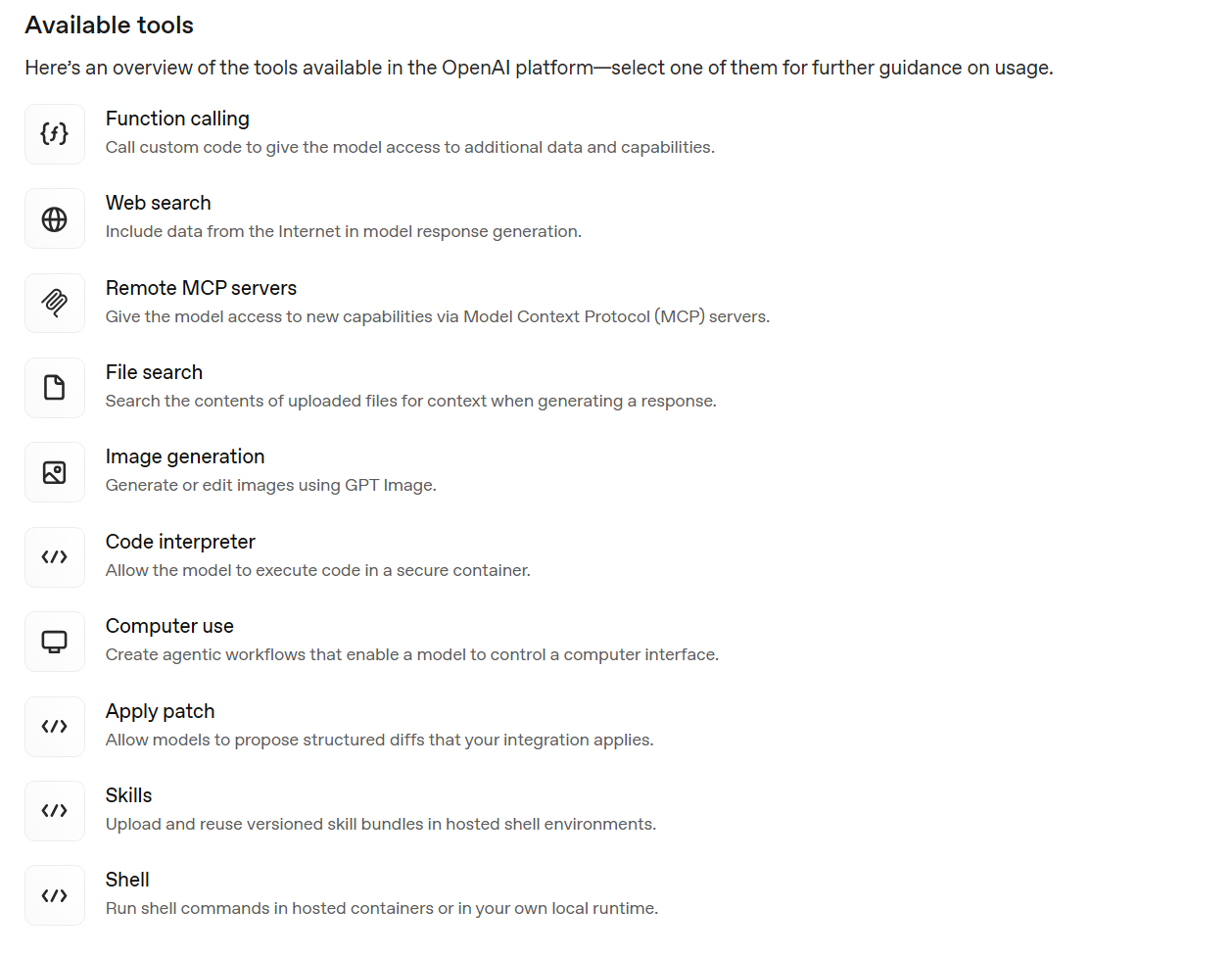
个人感觉,新增的这些tool或者mcp的核心目的都是为了把客户端的一部分工作,放到server端,减少用户自己处理的逻辑和负担,但是这都属于应用层的东西,其他的模型供应商大概率不会去对齐这些功能。这样以后很难切换其他供应商了。并且这里面很多功能还需要调用其他接口专门创建资源,比如container等。最有用的工具,目前来看是web_search,其他的比较一般。
anthropic也提供了一些内建工具,如下,也有web_search web_fetch等,不过稍有不同的是bash工具的type不是server_tool_use,在真正使用的时候,请自行调研每一种工具是在客户端还是服务端触发,以及收费标准:

对于responses的响应格式如下:
{
"id": "resp_67ccd7eca01881908ff0b5146584e408072912b2993db808",
"object": "response",
"created_at": 1741477868,
"status": "completed",
"completed_at": 1741477869,
"error": null,
"incomplete_details": null,
"instructions": null,
"max_output_tokens": null,
"model": "o1-2024-12-17",
"output": [
{
"type": "message",
"id": "msg_67ccd7f7b5848190a6f3e95d809f6b44072912b2993db808",
"status": "completed",
"role": "assistant",
"content": [
{
"type": "output_text",
"text": "The classic tongue twister...",
"annotations": []
}
]
}
],
"parallel_tool_calls": true,
"previous_response_id": null,
"reasoning": {
"effort": "high",
"summary": null
},
"store": true,
"temperature": 1.0,
"text": {
"format": {
"type": "text"
}
},
"tool_choice": "auto",
"tools": [],
"top_p": 1.0,
"truncation": "disabled",
"usage": {
"input_tokens": 81,
"input_tokens_details": {
"cached_tokens": 0
},
"output_tokens": 1035,
"output_tokens_details": {
"reasoning_tokens": 832
},
"total_tokens": 1116
},
"user": null,
"metadata": {}
}
核心内容是output字段,是本次请求的大模型的回复内容。
5 openrouter
不同的供应商会对上述俩家ai领头羊公司提供的接口进行兼容,但是也如上述,很多参数是这俩公司自己上层提供的额外服务,其他供应商是不会有的。openrouter是一个对很多供应商提供的统一路由的服务商,所以他就需要抽象出更通用的参数格式。所以这里我们看一下openrouter的接口定义。
5.1 openrouter的chat/completions接口
为了能兼容多个下游的供应商,openrouter的chat/completions接口,入参格式如下:
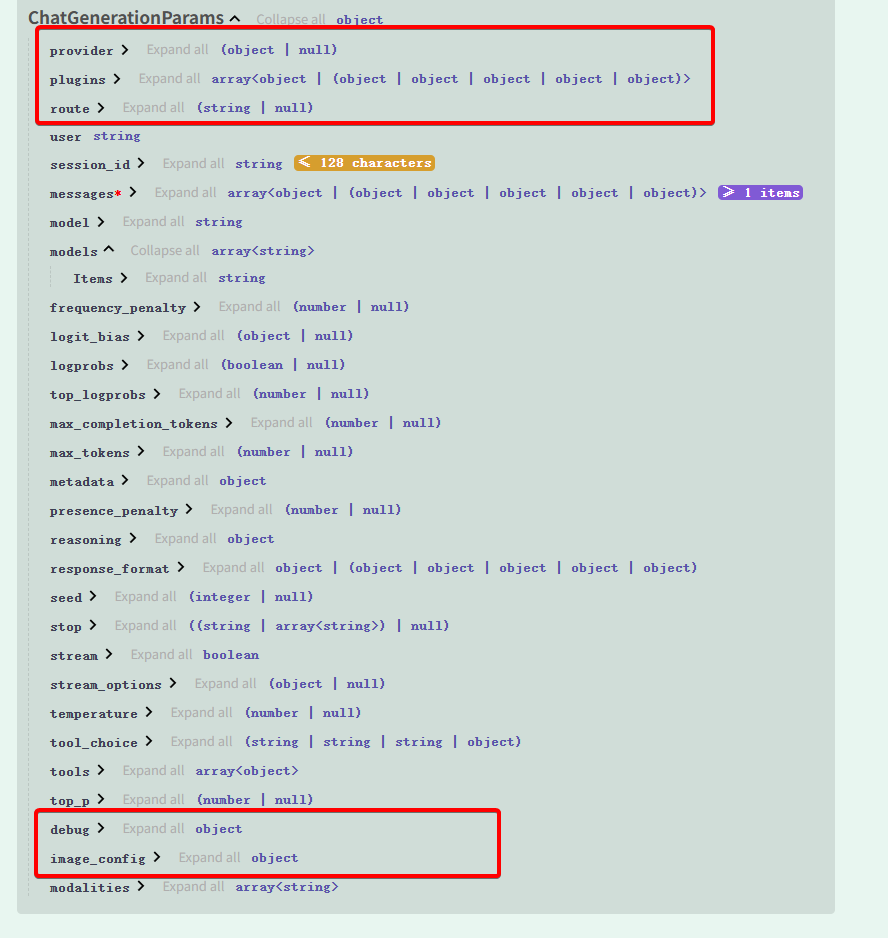
大部分核心参数和openai是对齐的,另外有一些路由专用的参数,例如provider指定特定的供应商,route指定特定的路由规则,plugins指定openrouter提供的插件,例如网页搜索插件,前面我们提到openai和anthropic都支持这个web_search的功能,但很多其他供应商是不支持的,所以openrouter在网关层添加了插件的功能,也可以添加网页搜索插件,他的工作原理是如果添加了这个网页搜索插件在入参中,网关层会先进行搜索,将搜索后的信息和用户原始信息,一起送到下游的供应商。
另外一些其他参数在or官方文档也给出了详细的解释,甚至还有视频解释,如果感兴趣,尤其是对模型采样、温度等参数的原理与效果感兴趣,可以去看看,文档。
此外我们看到openrouter删掉了openai的很多参数,例如prompt_cache相关的,那如果想要用这个参数,其实是可以在入参中指定的,参数会被透传到下游供应商。
5.2 openrouter的responses和messages兼容接口
因为很多应用开发的时候可能用了responses或messages接口,例如codex目前已经不支持completions接口,只支持responses接口。openrouter也提供了这两种形式的接口,这两个接口的格式就与openai和anthropic的接口参数一致了。
6 litellm
开源的转发工具litellm做了和openrouter类似的转发工作,不过他是一个开源项目,可以在本地运行,配置自己的下游多个供应商。在他的官网列出了多种供应商支持的参数列表,作为用户可以传这些参数,会转发到下游,当然有些下游不支持某些参数,就会被自动忽略,他的官网还给出了,目前一些供应商支持的参数列表。
| Provider | temperature | max_completion_tokens | max_tokens | top_p | stream | stream_options | stop | n | presence_penalty | frequency_penalty | functions | function_call | logit_bias | user | response_format | seed | tools | tool_choice | logprobs | top_logprobs | extra_headers |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Anthropic | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | |||||||||
| OpenAI | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Azure OpenAI | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| xAI | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ||||
| Replicate | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | |||||||||||||||
| Anyscale | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | |||||||||||||||
| Cohere | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | |||||||||||||
| Huggingface | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ||||||||||||||
| Openrouter | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ||||||||
| AI21 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | |||||||||||||
| VertexAI | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ||||||||||||||
| Bedrock | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ (model dependent) | ||||||||||||||
| Sagemaker | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ||||||||||||||
| TogetherAI | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | |||||||||||
| Sambanova | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | |||||||||||
| AlephAlpha | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ||||||||||||||
| NLP Cloud | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | |||||||||||||||
| Petals | ✅ | ✅ | ✅ | ✅ | |||||||||||||||||
| Ollama | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ||||||||||||
| Databricks | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | |||||||||||||||
| ClarifAI | ✅ | ✅ | ✅ | ✅ | ✅ | ||||||||||||||||
| Github | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ (model dependent) | ✅ (model dependent) | |||||||
| Novita AI | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | |||||||||||
| Bytez | ✅ | ✅ | ✅ | ✅ | ✅ | ||||||||||||||||
| OVHCloud AI Endpoints | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
6.1 litellm配置本地代理多个供应商
如果你有多个llm供应商可能是会员,或者有买一些代理等,也可以在本地配置一个litellm作为统一的入口网关。
他的用法比较简单,先安装
$ pip install litellm[proxy]
然后写一个配置文件:
general_settings:
disable_database: true
disable_analytics: true
disable_sessions: true
model_list:
- model_name: silicon/deepseek-v3.1
litellm_params:
model: openai/deepseek-ai/DeepSeek-V3.1
api_key: "your_api_key"
api_base: "https://api.siliconflow.cn/v1"
- model_name: silicon/deepseek-v3.2
litellm_params:
model: anthropic/deepseek-ai/DeepSeek-V3.2
api_key: "your_api_key"
api_base: "https://api.siliconflow.cn/v1"
general_settings是litellm的全局配置,我这里不需要复杂的管理所以把db和其他一些附加功能关闭了。然后model_list中是一些模型配置。
model_list是支持的模型下游列表,model_name是litellm对外提供的模型的名字,可以自己随便叫。litellm_params是调用下游供应商的配置。其中api_base是你的供应商提供的base_url,供应商可以是上面介绍的三种形式的api接口的任意一种,chat/completions,messages,responses都可以。
如果是chat/completions的话,model需要以openai/开头(并且不是openai/responses开头)。此时的原理是,转发的时候判断openai/开头,会将请求转换成chat/completions接口的请求格式,再转发给下游供应商。
如果是messages的话,model需要以anthropic/开头。此时的原理是,转发的时候判断anthropic/开头,会将请求转换成messages接口的请求格式,再转发给下游供应商。
如果是responses的话,model需要以openai/responses开头。此时的原理是,转发的时候判断openai/responses开头,会将请求转换成responses接口的请求格式,再转发给下游供应商。自己对外则同时提供chat/completions和messages两种接口。如果请求是responses接口的话,目前只能转发给支持responses的下游供应商。
如下图:
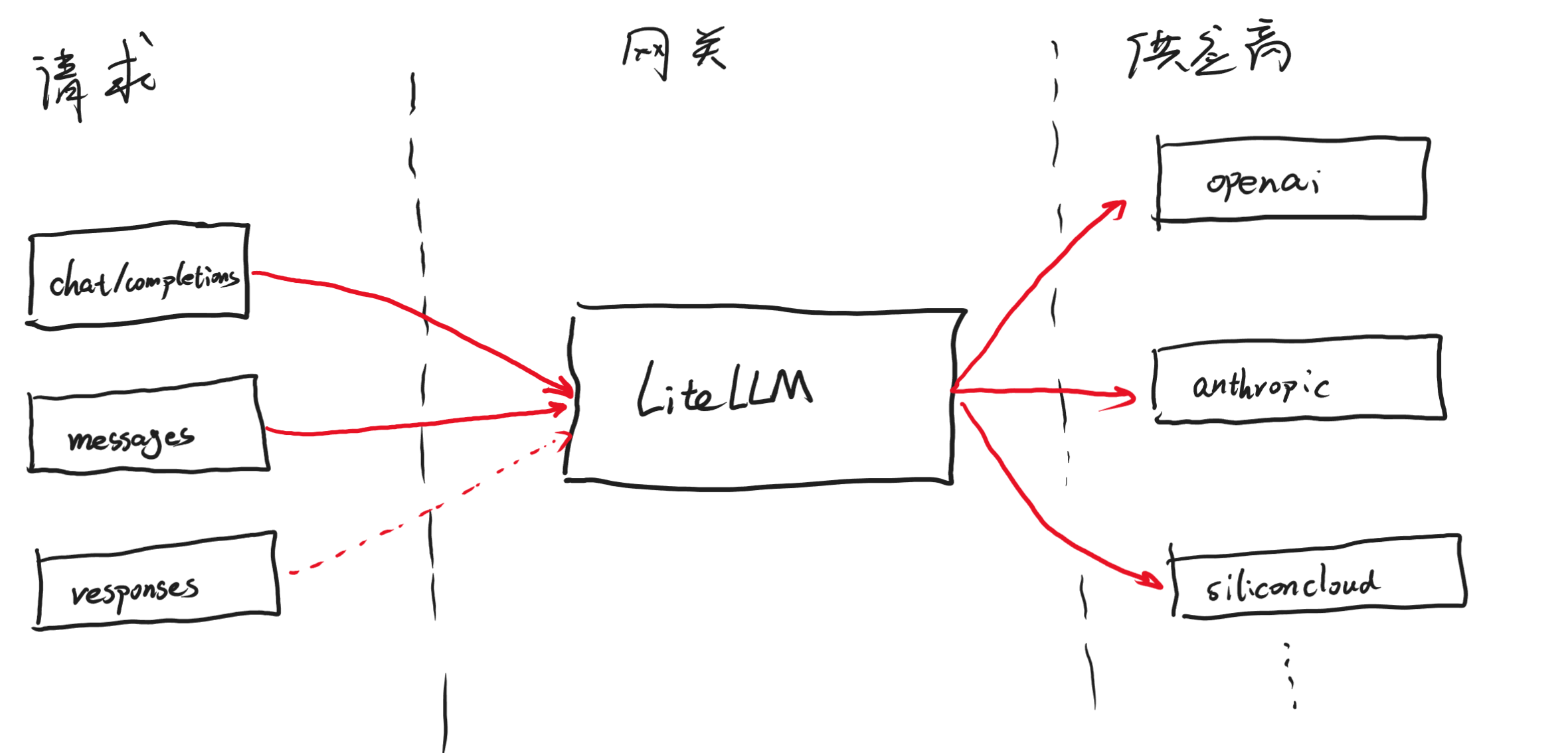
简言之,litellm可以代理多个供应商,对于主流接口chat/completions,messages的供应商都可以代理,并且可以同时对外暴露这两种接口,即使供应商是chat/completions接口,也会额外暴露messages接口类型。只需要在上面模型配置的时候,用合适的前缀即可,主流的供应商前缀就是openai,anthropic,azure等,可以参考官方文档介绍。而对于responses接口,litellm将其归为非主流接口,所以对他的支持是,主流接口的请求可以转换成responses接口请求,需要用openai/responses/开头的model_name,而非openai。并且也对外暴露responses接口,但是只用来转发,不能转换发到其他主流接口的供应商。