目录结构
用官网默认的方式安装clickhouse到linux系统后,数据的默认存储位置在/var/lib/clickhouse/data,到这个目录下可以看到如下结构,default和system是database的名字,默认就有这两个db,如果想要创建新的,可以用create database xxx;,也会多出xxx目录在这里。
root@ubuntu2404:/var/lib/clickhouse/data# ll
total 16
drwxr-x--- 4 clickhouse clickhouse 4096 Dec 13 16:27 ./
drwx------ 13 clickhouse clickhouse 4096 Dec 13 15:59 ../
drwxr-x--- 2 clickhouse clickhouse 4096 Dec 13 16:31 default/
drwxr-x--- 2 clickhouse clickhouse 4096 Dec 13 16:30 system/
我们在default库下创建一个user表:
CREATE TABLE user
(
id UInt64,
name String,
create_at DateTime,
email String,
gender Enum8('male' = 1, 'female' = 2, 'other' = 3)
)
ENGINE = MergeTree()
PARTITION BY toYYYYMMDD(create_at)
ORDER BY (create_at, id)
SETTINGS index_granularity = 8192,
min_bytes_for_wide_part = 0, -- 字节数阈值设为0
min_rows_for_wide_part = 0; -- 行数阈值设为0;
可以看到default目录下也会多出一个user子目录
root@ubuntu2404:/var/lib/clickhouse/data/default# ll
total 8
drwxr-x--- 2 clickhouse clickhouse 4096 Dec 14 05:16 ./
drwxr-x--- 4 clickhouse clickhouse 4096 Dec 13 16:27 ../
lrwxrwxrwx 1 clickhouse clickhouse 52 Dec 14 05:16 user -> ../../store/2ff/2ff4ec8b-f797-4f33-8607-141c96812ad1/
然后我们在user表中插入100w条测试数据,create_at的取值是过去10天随机取
INSERT INTO user (id, name, create_at, email, gender)
SELECT
number + 1 as id,
concat('user_', toString(number + 1)) as name,
now() - toIntervalDay(rand() % 10) as create_at,
concat('user_', toString(number + 1), '@example.com') as email,
if(number % 3 = 0, 'male', if(number % 3 = 1, 'female', 'other')) as gender
FROM numbers(1000000);
此时在user目录下查看文件结构,可以看到有2025xxx_a_b_c这样的目录结构,每个目录我们称之为一个Part,前面2025xxxx的部分就是这个Part所在的分区Partition,前者是物理概念,实际存在的文件夹,后者是逻辑概念。然后a和b是指当前这个Part下最小和最大的数据块序号,从当前插入100w数据之后的结果来看,我们发现目前每个Partition只有一个Part目录,并且每个Part目录的数据块都只有一个(a和b始终相等)。这是因为我们只有一句批量插入的sql,后台没有进行过任何merge.
root@ubuntu2404:/var/lib/clickhouse/data/default/user# ll
total 56
drwxr-x--- 13 clickhouse clickhouse 4096 Dec 14 05:24 ./
drwxr-x--- 3 clickhouse clickhouse 4096 Dec 14 05:23 ../
drwxr-x--- 2 clickhouse clickhouse 4096 Dec 14 05:24 20251205_3_3_0/
drwxr-x--- 2 clickhouse clickhouse 4096 Dec 14 05:24 20251206_8_8_0/
drwxr-x--- 2 clickhouse clickhouse 4096 Dec 14 05:24 20251207_10_10_0/
drwxr-x--- 2 clickhouse clickhouse 4096 Dec 14 05:24 20251208_9_9_0/
drwxr-x--- 2 clickhouse clickhouse 4096 Dec 14 05:24 20251209_1_1_0/
drwxr-x--- 2 clickhouse clickhouse 4096 Dec 14 05:24 20251210_5_5_0/
drwxr-x--- 2 clickhouse clickhouse 4096 Dec 14 05:24 20251211_4_4_0/
drwxr-x--- 2 clickhouse clickhouse 4096 Dec 14 05:24 20251212_2_2_0/
drwxr-x--- 2 clickhouse clickhouse 4096 Dec 14 05:24 20251213_7_7_0/
drwxr-x--- 2 clickhouse clickhouse 4096 Dec 14 05:24 20251214_6_6_0/
drwxr-x--- 2 clickhouse clickhouse 4096 Dec 14 05:23 detached/
-rw-r----- 1 clickhouse clickhouse 1 Dec 14 05:23 format_version.txt
我们再插入一条数据:
INSERT INTO user (id, name, email, gender, create_at) VALUES
(999, 'new_user', '[email protected]', 'male', now());
重新查看目录结构,会发现多了一个20251214_11_11_0的目录,这其实就是MergeTree的工作方式,新插入的数据,哪怕只有一条,也是新创建一个Part。这里新的Part目录只有一条数据,独占了数据块11。
root@ubuntu2404:/var/lib/clickhouse/data/default/user# ll
total 60
......
drwxr-x--- 2 clickhouse clickhouse 4096 Dec 14 05:31 20251214_11_11_0/
drwxr-x--- 2 clickhouse clickhouse 4096 Dec 14 05:24 20251214_6_6_0/
MergeTree会后台进行自动的Merge操作,把20251214_11_11_0和20251214_6_6_0合并为一个目录,我们也可以强制触发这个合并,通过sql:
OPTIMIZE TABLE user
此时再查看目录,就会发现又多出了一个20251214_6_11_1目录,这就是把_6和_11合并了,因为是经历了一次合并,所以后缀是_1其他没有合并的都是_0,此时原来的两个目录还没有被删除,已经被标记为不可用了,等待几分钟后会被自动删除。
root@ubuntu2404:/var/lib/clickhouse/data/default/user# ll
total 64
......
drwxr-x--- 2 clickhouse clickhouse 4096 Dec 14 05:31 20251214_11_11_0/
drwxr-x--- 2 clickhouse clickhouse 4096 Dec 14 05:34 20251214_6_11_1/
drwxr-x--- 2 clickhouse clickhouse 4096 Dec 14 05:24 20251214_6_6_0/
这就是基础的目录结构了,clickhouse的Partition是个重要的逻辑概念,每个Partition会对应一个或者多个Part目录,这些Part目录最终会合并为一个目录,但是实际合并的过程都是异步的,因而每个Partition有多个Part是常态。
Part中的文件
进入任意一个Part目录,我们查看一下文件信息,如下:
root@ubuntu2404:/var/lib/clickhouse/data/default/user/20251205_3_3_0# ll
total 1576
drwxr-x--- 2 clickhouse clickhouse 4096 Dec 14 05:24 ./
drwxr-x--- 15 clickhouse clickhouse 4096 Dec 14 05:34 ../
-rw-r----- 1 clickhouse clickhouse 852 Dec 14 05:24 checksums.txt
-rw-r----- 1 clickhouse clickhouse 266 Dec 14 05:24 columns_substreams.txt
-rw-r----- 1 clickhouse clickhouse 153 Dec 14 05:24 columns.txt
-rw-r----- 1 clickhouse clickhouse 5 Dec 14 05:24 count.txt
-rw-r----- 1 clickhouse clickhouse 1830 Dec 14 05:24 create_at.bin
-rw-r----- 1 clickhouse clickhouse 129 Dec 14 05:24 create_at.cmrk2
-rw-r----- 1 clickhouse clickhouse 10 Dec 14 05:24 default_compression_codec.txt
-rw-r----- 1 clickhouse clickhouse 572677 Dec 14 05:24 email.bin
-rw-r----- 1 clickhouse clickhouse 117 Dec 14 05:24 email.cmrk2
-rw-r----- 1 clickhouse clickhouse 3671 Dec 14 05:24 email.size.bin
-rw-r----- 1 clickhouse clickhouse 109 Dec 14 05:24 email.size.cmrk2
-rw-r----- 1 clickhouse clickhouse 66489 Dec 14 05:24 gender.bin
-rw-r----- 1 clickhouse clickhouse 103 Dec 14 05:24 gender.cmrk2
-rw-r----- 1 clickhouse clickhouse 402984 Dec 14 05:24 id.bin
-rw-r----- 1 clickhouse clickhouse 115 Dec 14 05:24 id.cmrk2
-rw-r----- 1 clickhouse clickhouse 1 Dec 14 05:24 metadata_version.txt
-rw-r----- 1 clickhouse clickhouse 8 Dec 14 05:24 minmax_create_at.idx
-rw-r----- 1 clickhouse clickhouse 472743 Dec 14 05:24 name.bin
-rw-r----- 1 clickhouse clickhouse 116 Dec 14 05:24 name.cmrk2
-rw-r----- 1 clickhouse clickhouse 3671 Dec 14 05:24 name.size.bin
-rw-r----- 1 clickhouse clickhouse 109 Dec 14 05:24 name.size.cmrk2
-rw-r----- 1 clickhouse clickhouse 4 Dec 14 05:24 partition.dat
-rw-r----- 1 clickhouse clickhouse 120 Dec 14 05:24 primary.cidx
-rw-r----- 1 clickhouse clickhouse 410 Dec 14 05:24 serialization.json
其中checksums.txt是验证文件,columnsxxx记录了列的描述信息,count.txt记录了当前Part总条数,default_compression_codec.txt记录了数据压缩方式,metadata_version.txt记录元数据的版本,serialization.json记录了数据进行序列化的一些说明,这些都是简单的元数据文件,我们可以直接跳过。
剩下的文件中,会有{column}.bin、{column}.cmrk2、{column}.size.bin和{column}.size.cmrk2这几个文件,这是因为clickhouse是列式存储,每一列的数据是单独存到一个文件中的,相比行存,列存有几个优势:
- 速度:对于大宽表,如果只需要选取部分字段,或者按照部分字段进行查询、聚合,就可以只对部分文件进行扫描,加快了速度。
- 磁盘:同一列往往有较高的相似度,可以对数据进行充分压缩存储,大大减少了空间占用。
其中{column}.bin是该列的数据文件,而{column}.cmrk2是压缩标记文件,其实是对.bin文件的辅助文件,用来标记当前bin文件中每个granule在文件中的偏移量信息,加快查找特定granule的速度。而xx.size.bin则是针对变长字段例如String/Array才会有的文件,用来记录字段长度。
minmax_create_at.idx记录了create_at字段在当前Part下的最小和最大值,可以做快速数据定位。primary.cidx文件在下面主键中介绍。
这里会有几个疑问:
1 granule是啥?
这是clickhouse存储和查询数据的最小单位,类似mysql的page,翻译过来是颗粒,在建表的时候index_granularity = 8192指定了一个颗粒有8192条数据,所以每次即使只查一条数据,也会把8192条数据读取出来。一个.bin文件中会有多个granule。
2 列式存储如何select * xx where name=xx
ch是granule对齐的,只要找到name列的granule序号和颗粒内偏移量,根据序号和偏移量就可以拿出其他列*对应的数据。
id.bin: [1,2,3,...,8192] [8193,8194,...,16384] [16385,...]
name.bin: [A,B,C,...,H] [I,J,K,...,P] [Q,...]
...
3 为什么我看到的目录下文件名是data.bin而不是每一列有个bin文件?
这是因为默认数据量较小的时候采用compact形式,当数据量达到一定程度,才会转换Wide格式(每一列一个bin),建表语句中min_bytes_for_wide_part = 0,min_rows_for_wide_part = 0,强制使用wide格式。
整体的结构就是这样:
|- Partition(20251205)
|- Part(20251205_5_5_0)
|- Granule1 (8192条数据) 【逻辑概念,实际上每个字段的granule在不同的col.bin文件中】
|- Granule2 (8192条数据)
|- ...
|- Part(20251205_6_11_1)
|- Granule4 (8192条数据)
|- Granule7 (8192条数据)
|- ...
|- ...
4 为什么minmax文件只记录了create_at字段
这是因为create_at是Partition相关的字段,默认只记录这个字段的minmax,如果想要对其他字段也记录minmax加快搜索,需要单独创建minmax skip index这个后面讲。
主键与排序
每个bin文件有多个granule,那么他们是按照什么顺序存储到文件中的呢?这就是建表语句中的ORDER BY(create_at, id),这就是先根据create_at排序,如果一样再用id进行排序。默认情况下主键就是ORDER BY的值,但是也可以单独指定,但是只能指定为ORDER BY的前缀匹配的值作为主键,例如ORDER BY(a,b,c,d)可以指定pk为(a,b),但是一般不需要单独指定。
primary.cidx记录了当前目录下每个granule的第一条数据的主键值,而不对每个数据都记录主键值,这种做法叫做稀疏索引,这样可以用较少的信息快速定位一个granule,是一种大数据量下的取舍和均衡。cidx文件的内容是这样:
granule_0: [create_at=2025-12-05T00:01:02, id=234]
granule_1: [create_at=2025-12-05T03:23:10, id=679]
granule_2: [create_at=2025-12-05T06:23:33, id=445]
granule_3: [create_at=2025-12-05T06:23:33, id=875]
...
此时如果已经定位到当前part,需要在当前part中搜索where create_at='2025-12-05T05:00:00'的数据,就可以直接定位到在g1这个颗粒中。
接下来我们思考,如果where id=235这个条件的话,是否能用主键?在mysql,如果联合索引是create_at,id那么根据最左匹配原则,指定id=235是无法使用索引的,但是clickhouse不同,在搜索数据的时候,使用的是granule排除法,例如id=235可以排除granule_2,因为和granule_3是同一个create_at,并且id是445大于235,这样整个granule2的id都会是445~875之间,就不可能含有235,因而可以排除granule2,但是其他的无法排除,所以我们可以得出结论clickhosue的主键,在查询的时候不用必须最左匹配也可以起到一定作用,但是最左匹配的效果肯定是最好的。
在开始自定义跳数索引之前,我们就可以看一下minmax -> partition -> pk的工作方式了:
explain indexes=1
select * from user where id = 123
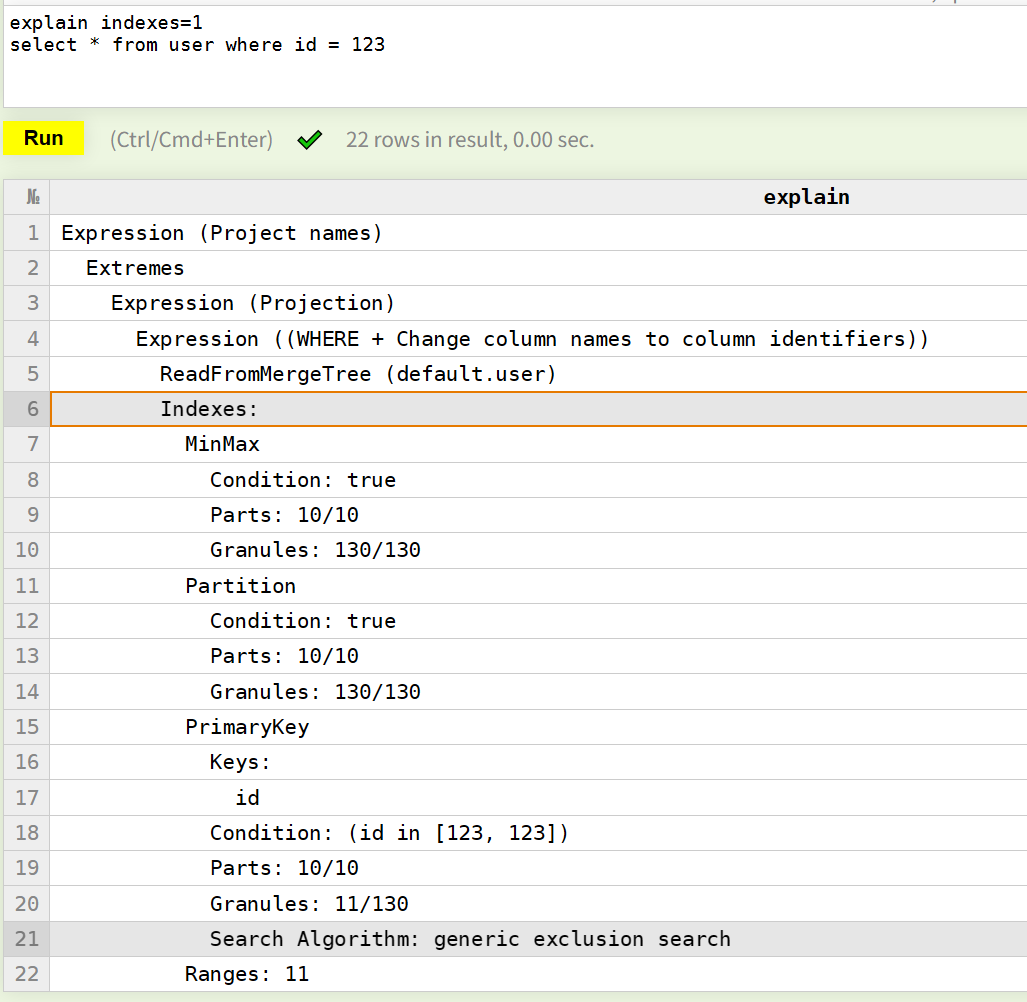
搜索id=123发现索引有3层:
Minmax对应minmax_create_at.idx文件,每个part的minmax会加载到内存中,这里作为第一层的过滤,因为我们没有指定create_at的条件,所以没有起到任何过滤作用,最后part:10/10 granule:130/130都保留了。Partition也是基于create_at的,这里Partition层基本作为Minmax层的一个补充验证,实际上Minmax的过滤已经涵盖了Partition,所以这里也没有做任何过滤。PrimaryKey对应primary.cidx文件,这个也是全部加载到内存中的,基于Order By(create_at, id),我们搜索中id=123,虽然没有最左匹配,但是根据数据的特性,还是起到了一些作用Parts:10/10 Granule:11/130,也就是虽然id=123还是在每个part中都有可能存在,但是每个part的granule进行了一些过滤,最后只剩了11个符合条件的granule,接下来会加载这11granule到内存,然后找到id=123的进行返回即可。
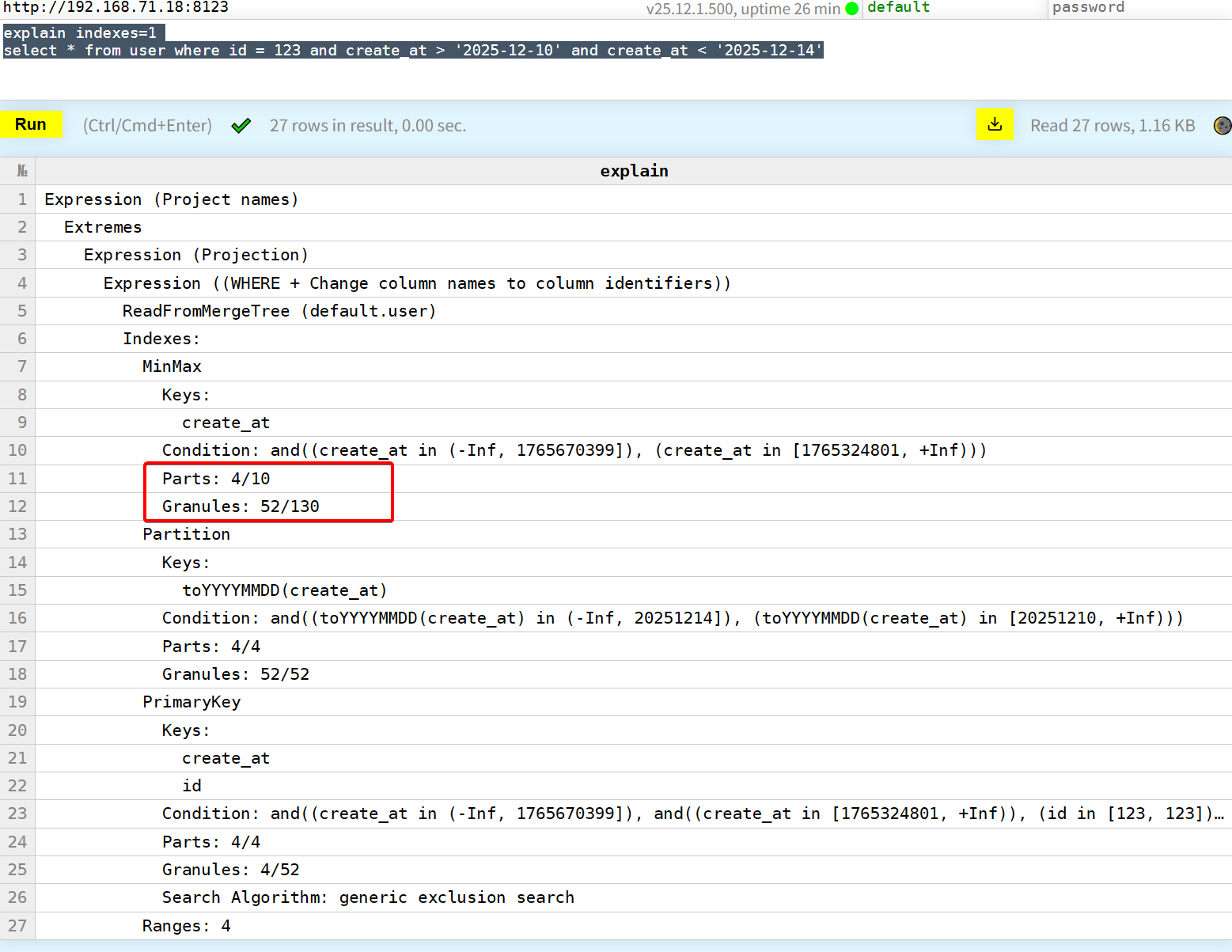
我们修改sql,添加一些create_at的搜索条件,此时就可以用到MinMax层的过滤了,当然Partition层还是起到了验证作用,这里没有过滤任何数据。
跳数索引(skip index)
除了主键之外,还可以对表单独建立跳数索引,也就是自定义的索引。跳数索引有多种类型:
1 minmax
与minmax_xxx.idx文件容易搞混淆,这是两个东西,跳数索引是手动创建的,idx文件是内置自动创建的,但是工作原理是类似的。
例如对我们的User表添加id的minmax索引。
ALTER TABLE user
ADD INDEX idx_id_minmax id TYPE minmax GRANULARITY 4;
-- 强制合并和生成索引文件
OPTIMIZE TABLE user FINAL;
这里GRANULARITY 4是每4个颗粒建立一个minmax索引,记录这4个颗粒的id的最大和最小值,用于快速确定数据有没有可能在当前4个granule中。
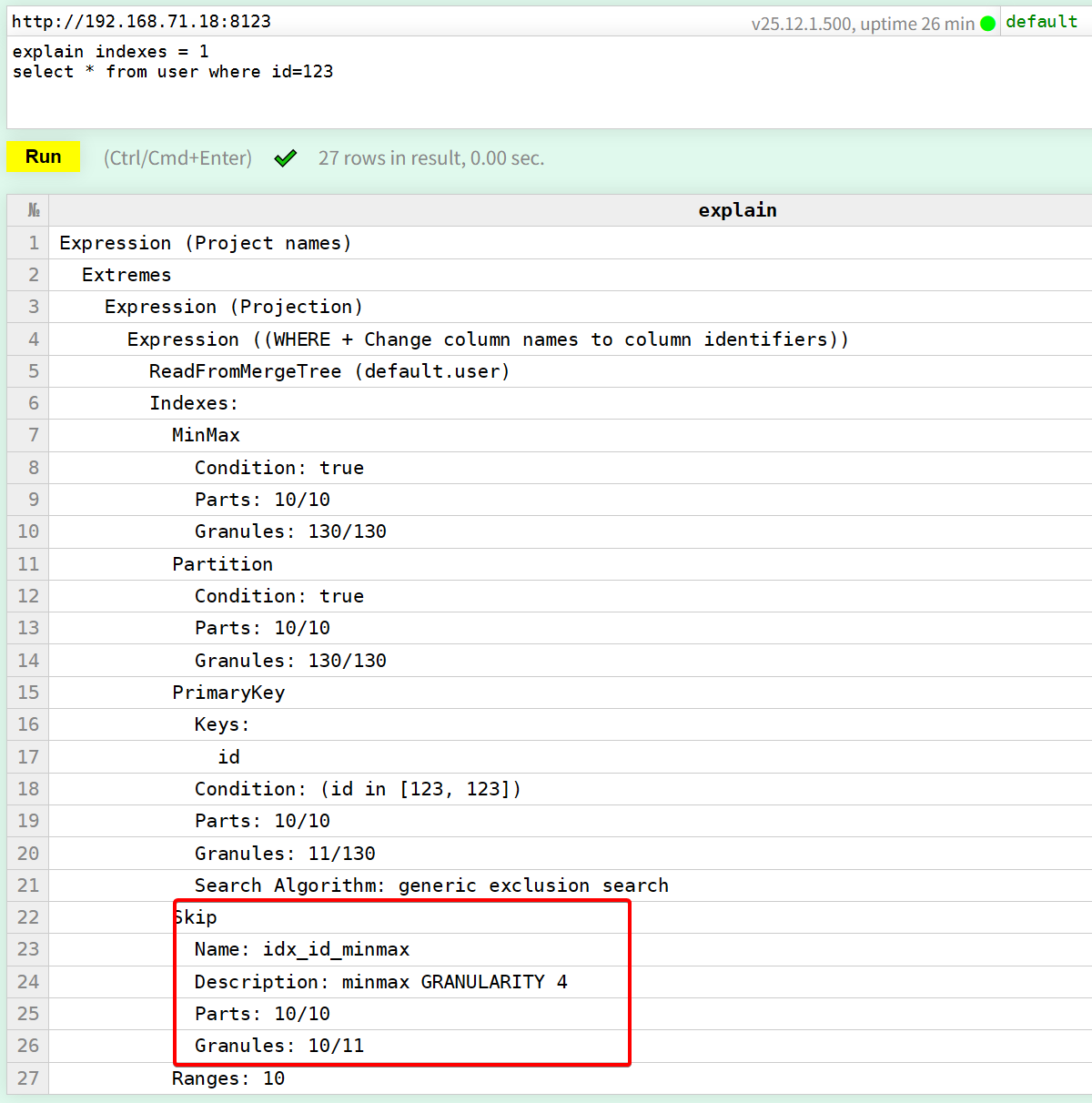
此时观察文件目录会多出2个文件,idx2文件中记录了当前part下每4个granule为一组,每组的id的最大和最小的值。
root@ubuntu2404:/var/lib/clickhouse/data/default/user/20251205_3_3_1_15# ll
total 1584
......
-rw-r----- 1 clickhouse clickhouse 58 Dec 14 09:52 skp_idx_idx_id_minmax.cmrk2
-rw-r----- 1 clickhouse clickhouse 68 Dec 14 09:52 skp_idx_idx_id_minmax.idx2
然后通过
explain indexes = 1
select * from user where id=123
此时可以看到explain结果中,多了一层Skip跳数索引,但是他的整体过滤效果一般10/11只过滤了1个颗粒,这是因为我们的数据是随机的,每个id是随机分布到过去10天的,也就意味着每个part目录中的id,都会是从0~100w均匀分布的所以minmax索引不太适合这种场景。
minmax一般要加在和order by具有正相关的字段上才有作用,对于独立的随机字段作用收效甚微,例如age name uuid,每个颗粒的minmax都是一个非常大的跨度,这样就起不到作用了。
2 set
set索引,是集合类型,语句形如:
ALTER TABLE record
ADD INDEX idx_status_set status TYPE set(100) GRANULARITY 4;
set的主要场景是针对“冷门”数据的查询场景,例如“大客户”,“VIP”,“删除”状态等,查询这种冷门数据的时候,大多数颗粒的set值都是不包含这个异常状态的,可以快速过滤掉。如果没有冷门数据,例如性别就是2个,年龄0-100的分布也相对均匀,set就没有作用了,因为每个颗粒的set值都是一样的。此外还需要查询的就是冷门状态才行,例如vip数据较少,但是查询的是非vip作为条件,那也起不到任何作用,因为每个颗粒中都含有非vip。
一开始的插入性别如果other占比不足1%,而查询又是查other的话是一种使用场景。
INSERT INTO user (id, name, create_at, email, gender)
SELECT
number + 1 as id,
concat('user_', toString(number + 1)) as name,
now() - toIntervalDay(rand() % 10) as create_at,
concat('user_', toString(number + 1), '@example.com') as email,
CASE
WHEN rand() % 100 < 1 THEN 'other'
WHEN (number + rand()) % 2 = 0 THEN 'male'
ELSE 'female'
END as gender
FROM numbers(1000000);
3 bloom_filter
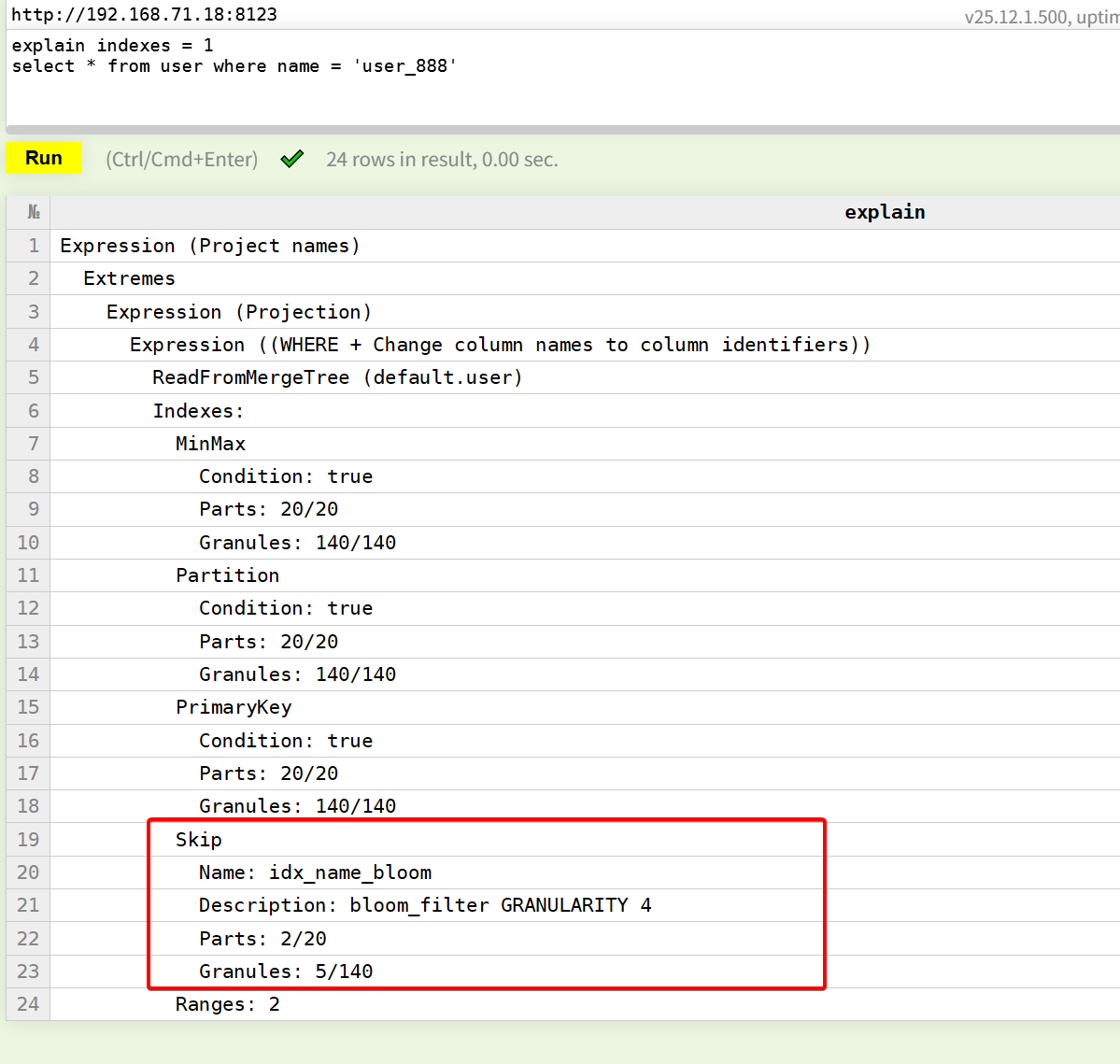
布隆过滤器主要就是针对随机数据,相比minmax和set要更加实用的一种索引。他是对指定的(1或多个)字段构建布隆过滤器,可以快速判断是否在当前颗粒中。例如对于用户名,建立布隆过滤器索引。
ALTER TABLE user
ADD INDEX idx_name_bloom name TYPE bloom_filter(0.01) GRANULARITY 4;
这里是对连续4个颗粒的name字段构建一个bf,假阳性率是0.01,假阳性率和数据规模,会最终决定bf的bit位数,即其占用的空间大小。
这里能看出bf的效果非常明显,bf的使用频率要比minmax和set高。
4 ngrambf_v1 & tokenbf_v1
简单介绍ngrambf_v1,他是为了支持模糊搜索like '%xxx%'加速的索引,ngram就是n个字符,例如n=3,对content字段添加索引,如果一条数据的content值是hello,那么会对hel ell llo三个字符串分别添加到布隆过滤器中,这样当sql为content like '%hel%'的时候就可以命中这个索引,实现加速,当然like '%hello%'也可以用到部分索引功能的。
ALTER TABLE test_table
ADD INDEX idx_content_ngram content TYPE ngrambf_v1(3, 256, 2, 0) GRANULARITY 3;
-- n=3, 布隆过滤器大小=256,hash函数个数=2,随机种子=0
tokenbf_v1和ngrambf_v1类似,只不过他不是以ngram进行滑动取bf,而是进行分词(英文分词)即按照空格标点等分割hello world会对hello和world建立bf索引。这样可以支持按照完整单词的搜索。